启动一个最简单的Serverless
介绍
在这个章节中你将会了解到如何启动一个最简单的Serverless服务, 你将会学习到如何创建一个Serverless,如何部署这个Serverless,以及如何调用这个Serverless。 并了解一些和Serverless 相关的计费的规则。
创建一个Serverless
我们做的第一步是创建一个由系统提供模板(镜像)的Serverless, 这个Serverless 的功能是利用Whipser 模型完成一个语音转文本的任务。
首先,你需要登录到Sprite的控制台。如果你还没有账号,请点击这里注册一个账号。 登录了之后,你可以看到如下的界面, 点击左侧的Serverless,然后点击新增Serverless。
请你确保你的余额足够, Serverless 的Worker启动会消耗你的余额。平台要求创建一个Serverless,必须保证余额高于 10元。

在新增 Serverless 页面,你需要填写一些基本的信息,比如Serverless的名称,描述等,具体的选项如下:
- Serverless名称:你的Serverless的名称,我们在这里输入
whisper-serverless。 - GPU规格: 选择你的Serverless的GPU规格,我们在这里选择
4090D-8xsmall-4-1。 - Worker基本信息:
- 活跃Worker数量:你的Serverless的一直保持活跃Worker数量,比如
1, 也可以为0, 如果为0, 在没有请求到来时, 所有的Worker都会停止不再启动,这样可以在请求还未访问的时候,节约你的成本。但是因为启动GPU, 加载模型往往都需要时间,所以这样配置可能会导致第一个用户请求的返回较慢,从而降低用户的使用体验。 用户体验和成本你需要做出一个选择。因为是演示,我们这里设置为0。 - 最大Worker数量:你的Serverless的最大Worker数量,比如
5。Serverless 的最大卖点是可以根据你的请求量自动扩容,但是因为GPU的资源是有限的,所以你需要设置一个最大的Worker数量,以免你的账户被恶意攻击。同时,如果太大的worker数量也会给你来较高的GPU成本。本身serverless 对请求是做了排队的处理。所以你可以根据你的业务需求来设置这个值。因为演示,我们这里选择为2 - 每个Worker GPU数量: 保留为1, 不用关心
- 空闲时长: 当Worker 空闲多久后,会自动停止, 默认值为300秒, 也就是5分钟。 你可以根据你的业务需求来设置这个值。你可以根据这个值调整和平衡你的成本和用户体验。这个值越长,用户体验应该越好,但是成本也会越高。因为演示,我们这里选择默认值。
空闲时长是当Worker空闲达到指定时间进行自动缩容的时长。空闲时间是 worker 没有请求处理时的空闲时间。当有请求处理时,空闲时间总是0。空闲时长的起始时间是从启动时就开始计时, 收到请求时,系统会更新空闲时长的起始时间的时间戳。 请合理的设置这个值,避免出现程序启动时间过长, 导致数据未处理就被认为空闲过长,平台将worker停止。 这句话的含义是, 空闲时长需要大于一次请求的处理时间。
- 活跃Worker数量:你的Serverless的一直保持活跃Worker数量,比如
- 伸缩策略: 伸缩策略有两种方式, 按请求数量伸缩或按请求等待时长进行伸缩, 两个伸缩策略只能二选一。
- 请求数量伸缩: 你可以设置一个阈值,这个请求数量是指在等待队列中等待的请求数量。当请求数量超过这个阈值时,会自动增加Worker数量,因为演示,我们这里选择按请求等待时长伸缩。并设置成等待数量为1
- 请求等待时长伸缩: 你可以设置一个阈值,这个请求等待时长是指在等待队列中等待的请求的等待时长。当请求等待时长超过这个阈值时,会自动增加Worker数量。
- 模板配置: 这里是可以选择你自定义的模板,模板必须被封装成为镜像,然后使用我们框架进行开发。 考虑到这只是一个快速上手的教程,我们这里选择系统提供的模板,选择
Whisper模板。 这个模板是由我们提供的一个语音转文本的模型,你可以直接使用。 - 挂载存储: Serverless 的Worker可以在启动的时候挂载存储,这样你可以在你的Worker中读取这个存储。这个存储是可以是读写的存储,你可以在这里挂载你的模型,数据等,或者存放你训练好的结果。因为我们这里使用的是系统提供的Whisper模板,这个模板只涉及到简单的推理并没有训练活持久化的数据写入,所以我们不需要挂载存储。
最终配置好的如下图: 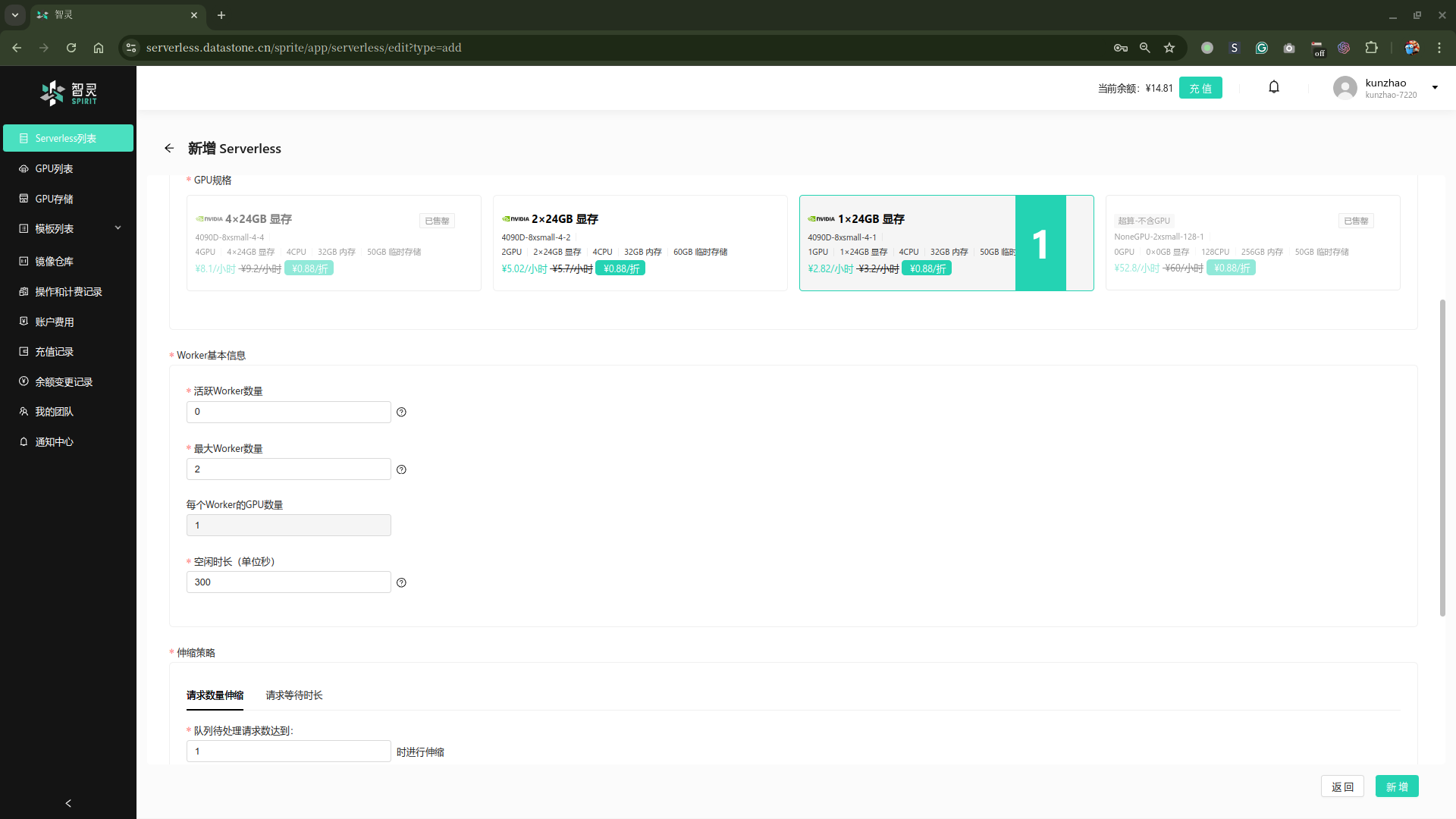
点击确定,完成Serverless的创建。创建完成后, 在Serverless 列表页面出现一张代表serverless的卡片。在这张卡片中我们需要注意的Serverless ID这个API的调用中会用到。如下图:
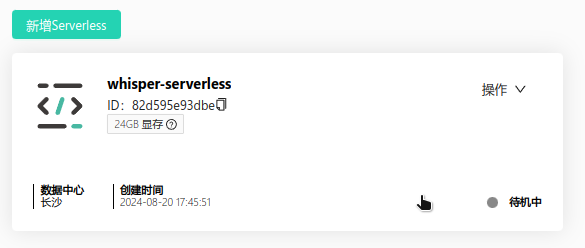
在这个卡片中我们可以观察到如下的关键信息:
- ID: 这个Serverless的ID, 他决定了serverless 调用的入口。通过id旁的复制图标,可以快速复制这个ID。
- 显存: 这个Serverless将会使用的显存容量。
- 状态: 右下角显示了这个Serverless的状态, 当Serverless 所有的Worker都处于空闲状态时,Serverless的状态会变为
待机中,就像上图显示的那样。一但有请求到来时,Serverless的Worker 被唤起并正常运行时,Serverless的状态会变为运行中。 - 操作: 你可以在这里对Serverless进行一些操作,比如查看Serverless的详情,删除, 编辑Serverless的信息。
设置Serverless的API Key
调用Serverless 必须要有API Key, 这个API Key 是用来验证你的请求是否合法的。因此需要为每个Serverless 生成独立的API Key来进行调用。 生成API方式如下:
- 点击Serverless卡片右上角的操作, 弹出下拉菜单, 选择详情, 如下图:
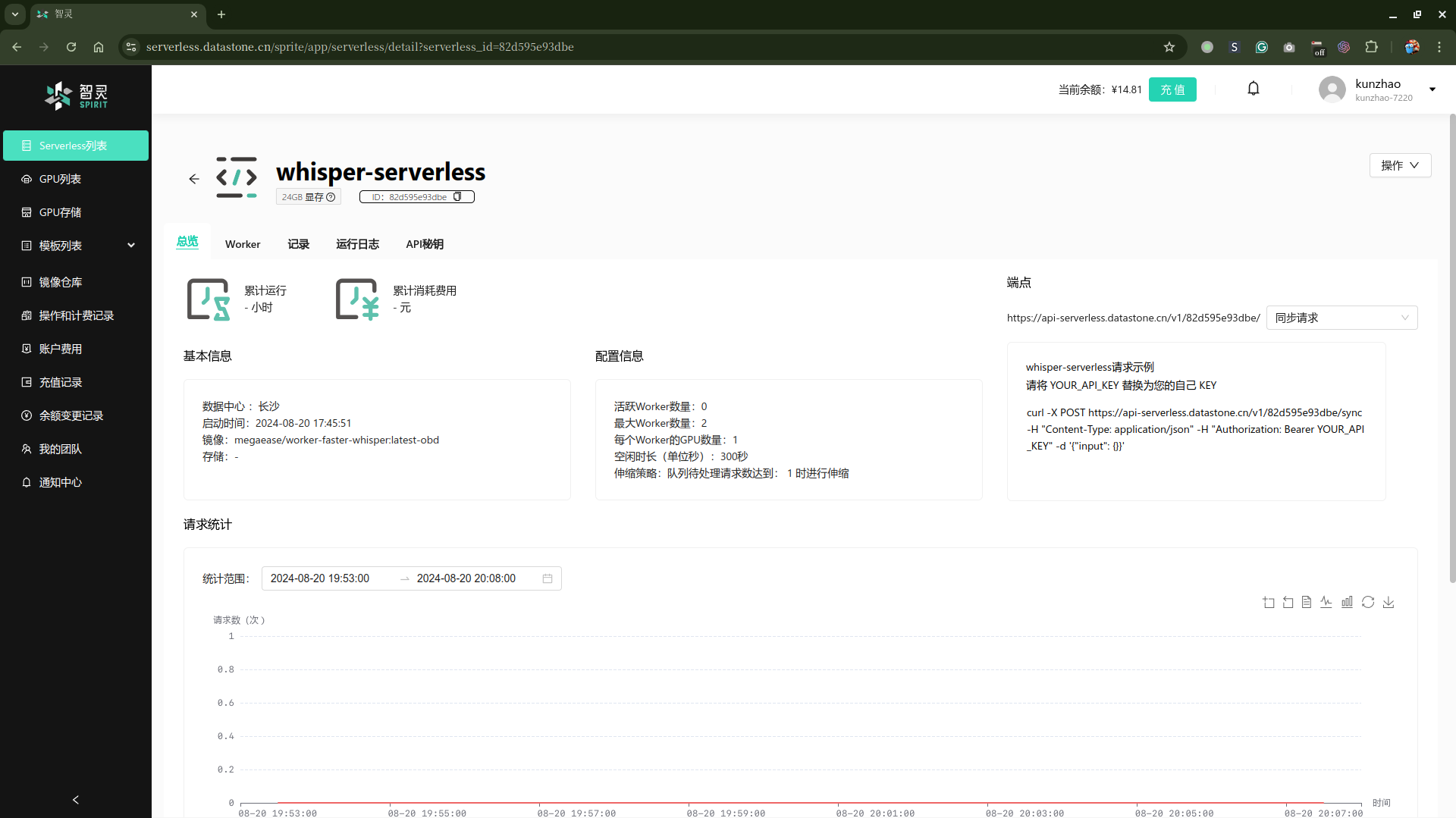
- 单击API 密钥选项卡, 然后点击
创建密钥按钮, 在弹出菜单中,可以通过过期时间限制,选择密钥的过期时间, 权限选择只读或读写,并输入密钥的描述, 点击确认按钮生成密钥 - 在弹出的对话框中, 你可以看到生成的API Key, 你可以通过复制按钮复制这个API Key。请注意, 这个API Key 只会显示一次, 请妥善保存这个API Key, 以免丢失。
调用Serverless
现在你有了Serverless 和Serverless的API Key, 你可以通过API Key来调用Serverless。 你可以使用任何的HTTP请求工具, 比如curl, postman, 或者你的代码来调用Serverless。 这里我们使用curl来调用Serverless。 Sprite 平台的Serverless 提供如下的调用方式:
同步 sync请求
同步调用, 你的请求会被阻塞, 直到Serverless返回结果。
HTTP Path
/v1/serverless/{serverless_id}/sync:
其中 serverless_id 就是你的Serverless的ID。不同的Serverless ID不同, 可以从Serverless 卡片上直接拷贝,或者从Serverless详情页面中查看并拷贝。
HTTP Method
POST
HTTP HEADER
| Key | Value | 备注 |
|---|---|---|
| Content-Type | application/json | |
| Authorization | Bearer | API 密钥, 上一章节中通过API密钥生成的唯一的密钥 |
HTTP Body
| Key | 类型 | 备注 |
|---|---|---|
| input | object | 输入参数, 这个参数是根据你的Serverless的模板而定, 你可以在Serverless的详情页面中查看Serverless的模板, 以及输入参数的格式。Sprite 的框架会把整个input 的值,解析成dict 对象传个你的Serverless 处理主程序 |
| webhook | string | 回调参数, 这个参数是用来接收Serverless的结果的, 你可以在这个参数中设置一个URL, 当Serverless处理完成后, 会把结果通过这个URL回调给你。 |
例如
{
"input":{
"audio":"https://dl.sndup.net/krrty/audio_audio_chinese.wav",
"model":"large-v3"
}
}在这个例子中,我们可以通过如下的命令发送一段音频到Serverless中, 并让Serverless 为我们返回相应的文本,命令如下 (隐去`了涉及到密钥的数据信息):
curl -XPOST -H "Content-Type: application/json" \
https://api-serverless.datastone.cn/v1/82d595e93dbe/sync \
-H "Authorization: Bearer 312f2cde*****************a60c" \
--data '{"input": {"audio": "https://dl.sndup.net/krrty/audio_audio_chinese.wav", "model": "large-v3"}}'调用后, 我们会得到类似如下的返回(由于篇幅的问题, 数据做了裁剪):
{
"model": "large-v3",
"detected_language": "zh",
"device": "cuda",
"segments": [
{
"id": 1,
"seek": 1996,
"start": 0,
"end": 3.16,
"text": "院子门口不远处就是一个地铁站",
"tokens": [ 50365, 38358, 7626, 8259, 101, 18144, 1960, 3316, 250, 1787, 226, 5620, 20182, 10928, 165, 241, 223, 34155, 50523 ],
"temperature": 0,
"avg_logprob": -0.12390792498024561,
"compression_ratio": 1.1666666666666667,
"no_speech_prob": 0.153564453125
},
....
{
"id": 5,
"seek": 1996,
"start": 15.16,
"end": 19.3,
"text": "邮局门前的人行道上有一个蓝色的邮箱",
"tokens": [ 51123,3023,106,34703,8259,101,8945,29979, 8082, 6025, 5708, 2412, 20182, 164, 26152, 17673, 1546, 3023, 106, 11249, 109, 51330 ],
"temperature": 0,
"avg_logprob": -0.12390792498024561,
"compression_ratio": 1.1666666666666667,
"no_speech_prob": 0.153564453125
}
],
"transcription": "院子门口不远处就是一个地铁站 这是一个美丽而神奇的景象 树上长满了又大又甜的桃子 海豚和鲸鱼的表演是很好看的节目 邮局门前的 人行道上有一个蓝色的邮箱",
"translation": null,
"word_timestamps": null
}异步 async
异步调用, 你的请求会被立即返回, 但是Serverless的结果会通过回调Webhook的方式返回。
获取状态 status
获取Serverless的状态, 你可以通过这个API来获取Serverless的状态, 比如Serverless的队列等待数, Serverless 特定请求的处理结果等(对于异步请求而言)。
查看Serverless 执行的情况和日志
了解Serverless 基本执行情况
你可以通过Serverless的详情页面来查看Serverless的执行情况和日志。 在Serverless的详情页面中,的总览页面中, 你可以查看到和这个Serverless 相关的队列的上队列运行数据, 例如队列上等待请求的数据。 请求的吞吐,以及相关的请求耗时等。 你可以通过这些数据来了解你的Serverless的运行情况。
如下图: 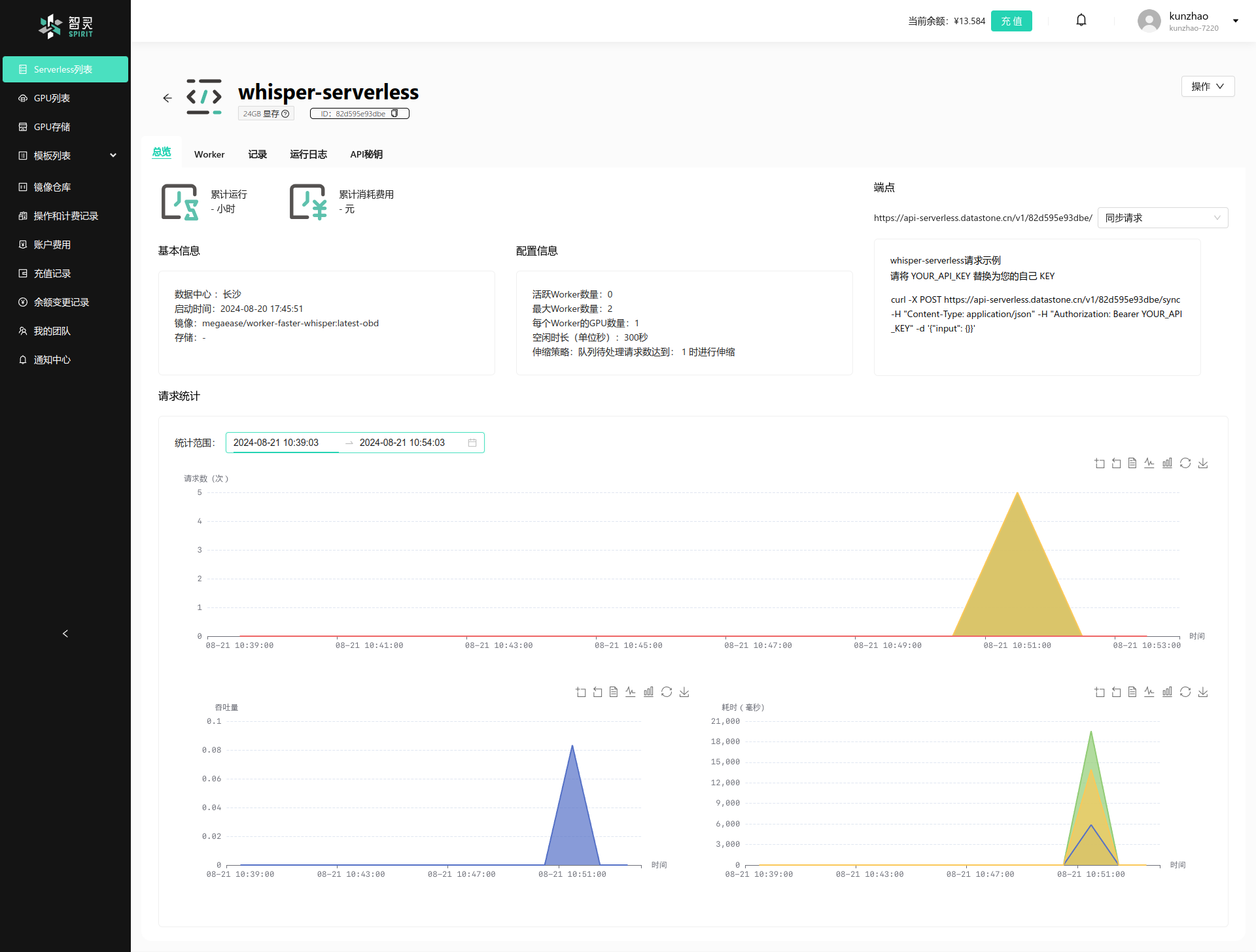
- Quening Count: 当前Serverless的等待队列中的请求数量, 反映请求在队列的等待时间点, 等待的时长, 等待的个数。
- Throughput 吞吐量: 通过移动平均计算的Serverless的吞吐量, 反映Serverless的处理能力。
- Latency 延迟: 通过移动平均计算的Serverless的延迟, 反映Serverless的处理速度。
了解Worker的运行情况
除了可以查看到Serverless的总体情况外, 你还可以查看到Serverless的Worker的运行情况。 在Serverless的详情页面中, 通过点击Worker 选项卡,你可以查看到Serverless的Worker的运行情况, 例如Worker的运行状态, Worker的GPU使用情况,Worker 的启停, worker的计费情况等。 你可以通过这些数据来掌握你的Serverless的Worker的实际运行情况。
为了能够体现出Worker的实际扩缩容情况,我们可以并发的多发几笔请求,然后查看Worker的运行数据。进入到Serverless 详情页,然后点击Worker选项卡,如下图: 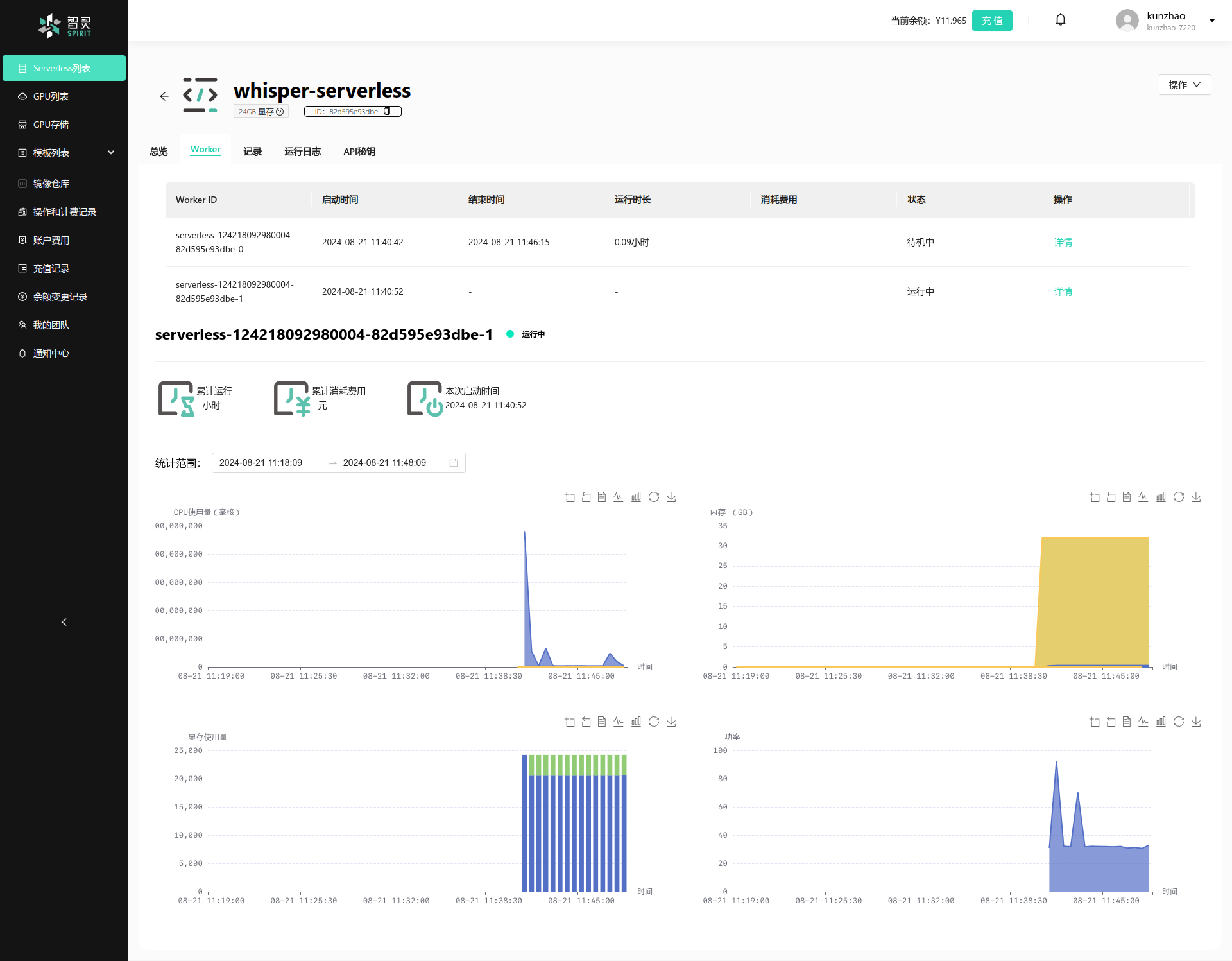
我们可以看到, 这个图中,的一worker 在一段时间内没有请求已经自动的缩容了, 这个是因为我们在创建Serverless的时候设置了空闲时长, 当某个Worker在设置的空闲时间内没有收到新的请求进行处理,那么Worker会自动停止。 你可以通过这个数据来了解你的Serverless的Worker的实际运行情况。 而另外一个worker 因为一直都有请求在处理, 所以他还是在运行的状态。 通过点击Worker列表里面的详情链接, 我们可以查看到这个Worker的运行详细信息, 例如这个Worker的GPU使用情况,Worker 的显存使用情况, Worker的功耗情况, Worker的内存使用情况等。
具体的图表含义如下:
- CPU 率用率: Worker的CPU使用率, 反映Worker的CPU使用情况。X轴是时间, Y轴是CPU使用率以豪核为单位。包含有三个指标,
CPUUsage,CPURequest,CPULimit, 分别代表:- CPUUsage: Worker实际使用的CPU豪核数
- CPURequest: Worker请求的CPU豪核数
- CPULimit: Worker的CPU限制豪核数
- Memory 内存: Worker的内存使用情况, 反映Worker的内存使用情况。X轴是时间, Y轴是内存使用率以GiB为单位。包含有三个指标,
MemoryUsage,MemoryRequest,MemoryLimit, 分别代表:- MemoryUsage: Worker实际使用的内存大小
- MemoryRequest: Worker请求的内存大小
- MemoryLimit: Worker的内存限制大小
- GPU 内存: Worker的GPU内存使用情况, 反映Worker的GPU内存使用情况。X轴是时间, Y轴是GPU内存使用率以GB为单位。包含有三个指标,
FreeFrameBufferinMB,UsedFrameBufferOfGPUinMB, 分别代表:- FreeFrameBufferinMB: Worker实际使用的GPU内存大小
- UsedFrameBufferOfGPUinMB: Worker 当前未使用的GPU内存大小
- GPU功耗: Worker的GPU功耗情况, 反映Worker的GPU功耗情况。X轴是时间, Y轴是GPU功耗以瓦为单位。包含有一个指标,
PowerUsageforthedeviceinwatts分别代表:- PownerUsageforthedeviceinwatts: Worker实际使用的GPU功耗大小。
Worker的操作和运行记录
在Serverless的详情页面中, 你可以查看到Serverless的Worker的计费明细。 在Serverless的详情页面中, 通过点记录费选项卡,你可以查看到Serverless的Worker的计费明细。Worker的启停明细等等记录。 进入记录费选项卡,默认是Worker的操作记录,即系统启动停止worker的具体时间, 所以你能看到系统在什么时间戳启动, 又在什么时间戳停止了。如下图:
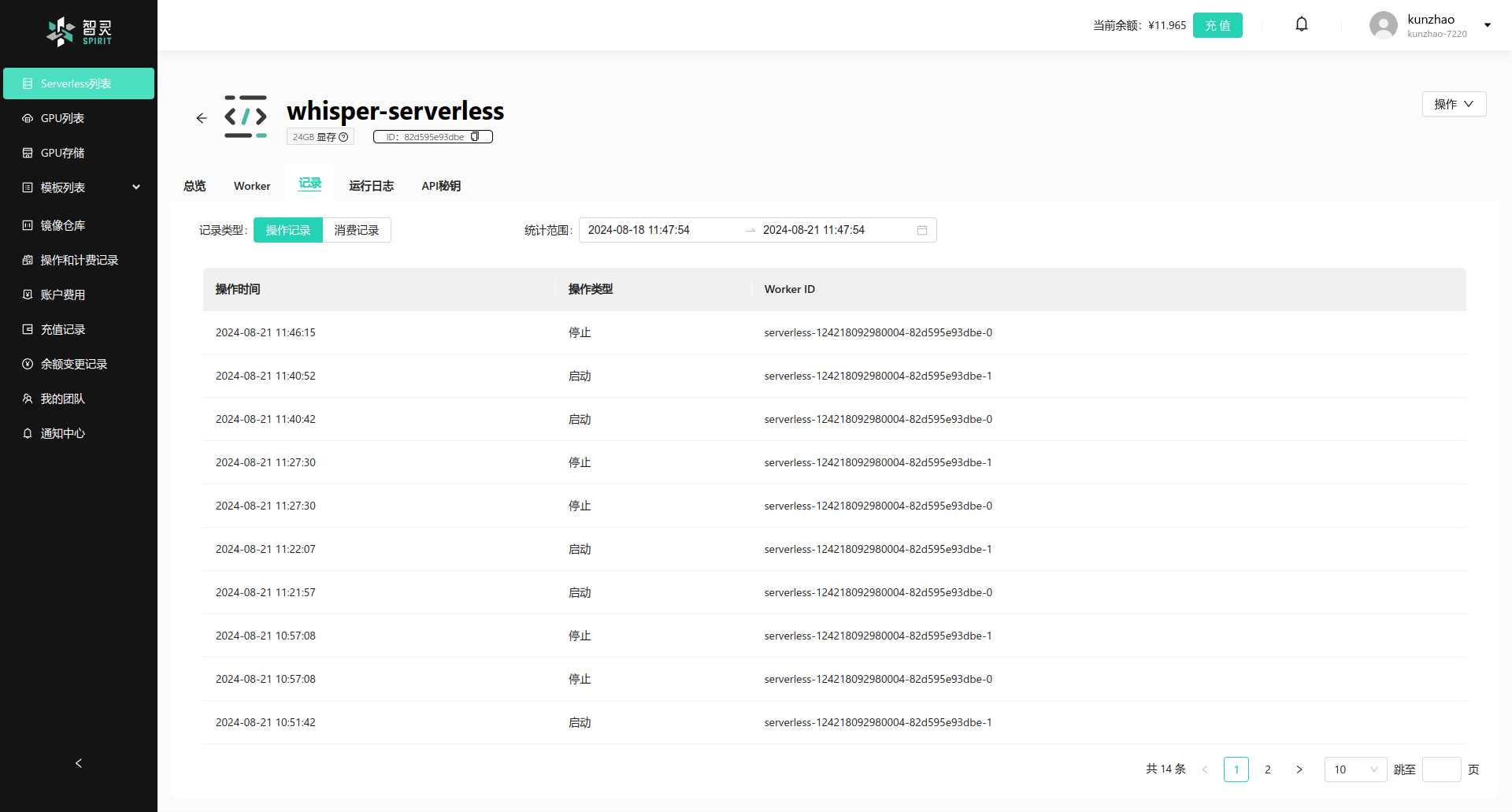
图表中的数据包含有三栏, 分别是:
- 操作时间: Worker的操作时间, 代表系统对Worker发出动作的时间戳。
- 操作类型: Worker的操作类型, 代表系统对Worker的操作类型, 包含有
启动,停止等。 - Worker ID: Worker的ID, 代表这个操作是针对哪个Worker的。
你也可以通过统计范围来查看不同时间段内的Worker的操作记录, 你可以通过选择不同的时间范围来查看不同时间段内的Worker的操作记录。
点击记录类型, 可以切换操作记录到计费记录, 计费记录是Worker的计费明细, 你可以查看到Worker的计费明细, 例如Worker的计费金额, Worker的计费时间等。 你可以通过这些数据来了解你的Serverless的Worker的计费情况。 如下图:
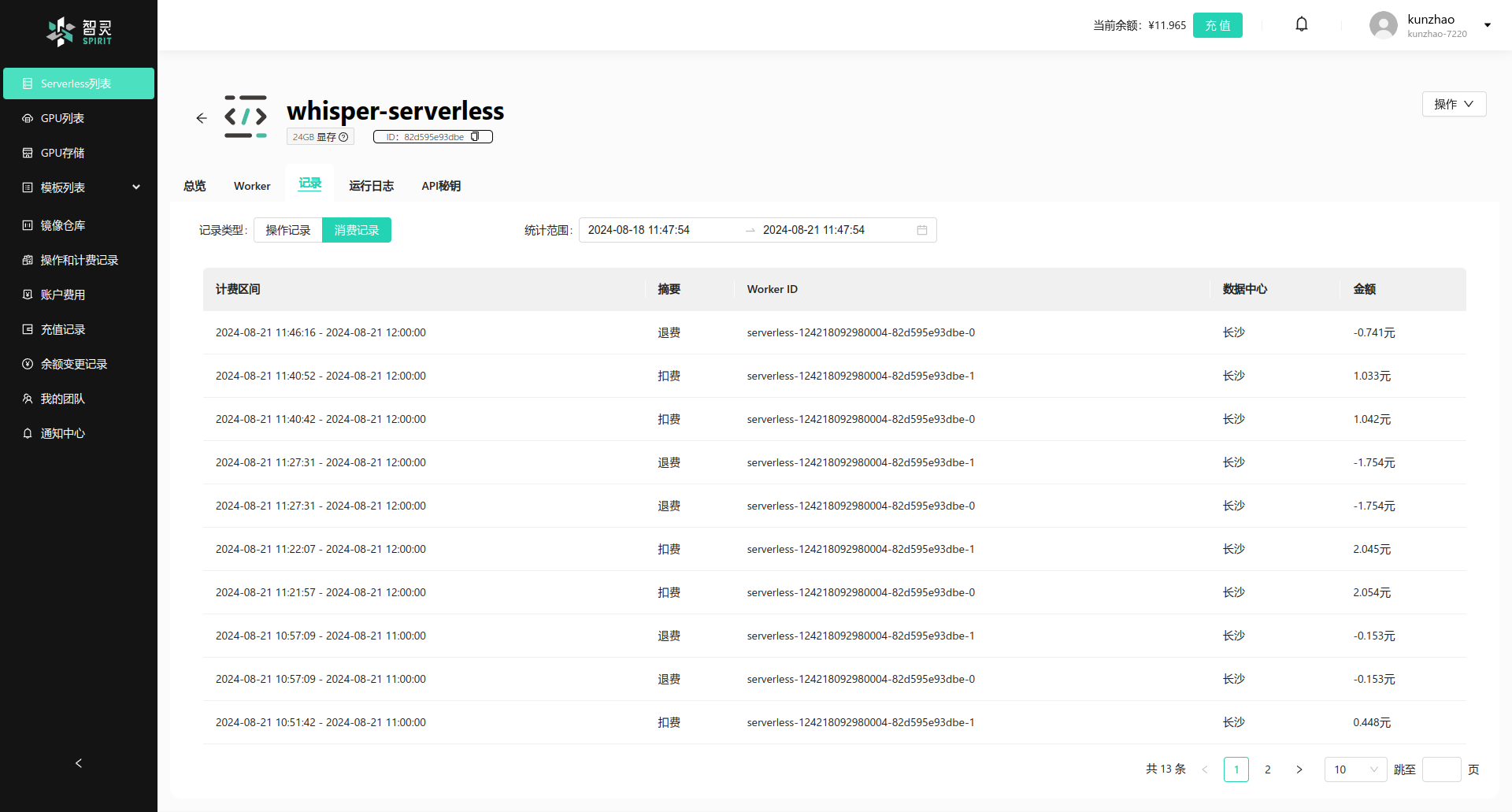
图表中的数据包含有五栏, 重要的数据是三栏,分别是:
- 计费时间: Worker的计费时间, 代表系统对Worker计费的时间戳。
- 摘要: Worker的计费摘要, 代表系统对Worker计费的摘要, 包含有
扣费,退费等。 - 计费金额: Worker的计费金额, 代表系统对Worker计费的金额。
- Worker ID: Worker的ID, 代表这个计费操作所针对哪个Worker的。
Serverless 计费方式
Serverless的计费方式是按照Worker的使用时间来按秒进行计费的, 也就是说, 你的Serverless的计费是按照你的Worker的实际使用时间来计费的。 你可以通过Serverless的详情页面来查看到Serverless的计费情况, 例如Serverless的计费金额, Serverless的计费时间等。 你可以通过这些数据来了解你的Serverless的计费情况。
但是具体的计费逻辑是这样的:
- Worker 启动才计费, Worker停止不计费。
- Worker 启动时, 平台会预扣启动时间戳到下一个整点的费用, 例如, 如果你的Worker在 10:30:30 启动, 那么平台会预扣到 11:00:00 的费用。
- Worker 停止时, 平台会退还预扣的费用, 例如, 如果你的Worker在 10:30:30 启动, 在 10:45:30 停止, 那么平台会退还 15分钟的费用。
- 具体的退换费用的计算方式是按照秒来计算的, 例如, 如果你的Worker在 10:30:30 启动, 在 10:45:30 停止, 那么平台会退还 15分钟的费用, 也就是 900秒的费用。
- 如果Worker运行过了一个整点,平台到了下一个整点时, 会再次预扣下一个整点的费用, 例如, 如果你的Worker在 10:30:30 启动, 平台先预扣到 11:00:00 的费用, 然后当Worker 继续运行到 11:00:00 时, 平台会再次预扣到 12:00:00 的费用。此时如果Worker在 11:15:30 停止, 那么平台会退还 45分钟的费用, 也就是 2700秒的费用。 在这个例子中, 平台会产生如下的计费记录:
| 计费时间 | 摘要 | 计费金额 | Worker ID |
|---|---|---|---|
| 2021-08-01 10:30:30 - 2021-08-01 11:00:00 | 扣费 | ¥xx.xx (30分钟,共计1800秒的预扣费 | serverless-worker-xxxxx-0 |
| 2021-08-01 11:00:00 - 2021-08-01 12:00:00 | 扣费 | ¥xx.xx (60分钟,共计3600秒的扣费 | serverless-worker-xxxxx-0 |
| 2021-08-01 11:15:30 - 2021-08-01 12:00:00 | 退费 | ¥xx.xx (44分钟30秒,共计2670秒的退费 | serverless-worker-xxxxx-0 |
Worker的日志
在Serverless的详情页面中, 你可以查看到Serverless的Worker的日志。 在Serverless的详情页面中, 通过点击日志选项卡,你可以查看到Serverless的Worker的日志页面,如下图: 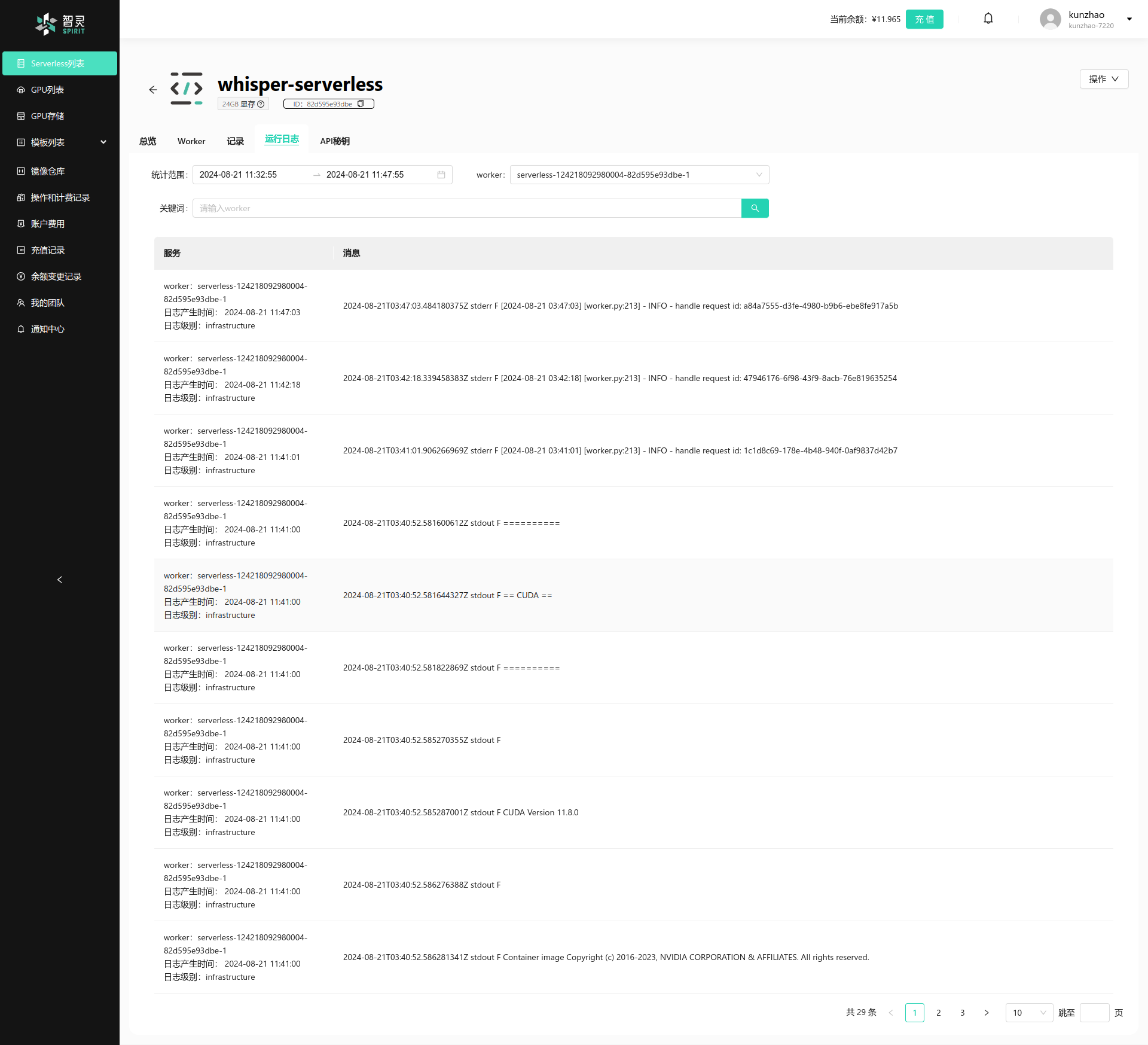
在Worker 日志选项卡中,你可以按照如下的几个不同维度来搜索你的Worker的日志:
- 时间范围: 你可以通过选择不同的时间范围来查看不同时间段内的Worker的日志。
- Worker: 查看特定Worker ID产生的日志信息。
- 关键字: 你可以通过输入关键字来搜索你的Worker的日志信息。
日志是分页方式进行显示并按时间倒序排序,所以如果日志过多,你可以通过翻页的方式来查看你的Worker的日志信息。 你可以通过这些数据来了解你的Serverless的Worker的日志情况。
总结
在这个章节中, 你学习到了如何创建一个最简单的Serverless服务, 你学习到了如何创建一个Serverless,如何部署这个Serverless,以及如何调用这个Serverless。 并了解一些和Serverless 相关的计费的规则。 在下一个章节中, 你将会学习到如何使用创建自己的Serverless模板, 并且部署这个Serverless模板。如何使用Sprite 提供的Serverless 框架来开发你的Serverless模板。