在智灵平台部署自定义 GPU 应用:以 AI Toolkit 为例
智灵平台虽然内置了 ComfyUI、Stable Diffusion、Jupyter Notebook 等常用应用模板,但用户的需求是多种多样的。本教程将指导您如何在智灵平台上部署一个带有 Web UI 的自定义 GPU 应用。
我们将以 AI 训练套件 AI Toolkit 为例,一步步进行讲解。请注意,本教程要求您部署的应用本身需要提供 Web UI 界面,以便通过浏览器访问。
准备工作
在开始之前,请确保我们已准备好以下几项:
- GPU存储:为了持久化应用数据(如模型、依赖库、训练成果等),防止实例重启后数据丢失,我们需要创建一个GPU存储并将其挂载到 GPU 实例。
- 基础镜像模板:我们需要一个纯净且支持开机自启脚本(Hook)的 GPU 环境。平台内置的 Jupyter Notebook 模板是理想的选择,因为它提供了干净的系统和便捷的 Hook 脚本。
- 目标应用:本次示例中,我们选用 AI Toolkit 作为部署目标。
- 排错能力:教程会尽量详尽,但实际操作中可能遇到各种意外情况,需要您耐心排查。解决未知问题的能力是不断实践积累的。
步骤一:创建GPU存储
首先,我们需要创建一个GPU存储,用于存放应用代码、Python 虚拟环境、数据集和模型等。
在智灵平台的 GPU存储 页面,点击 新增存储。
根据需求设置存储容量和挂载路径。通常情况下,默认的
/root挂载路径即可。容量不足时,后期可以随时扩容。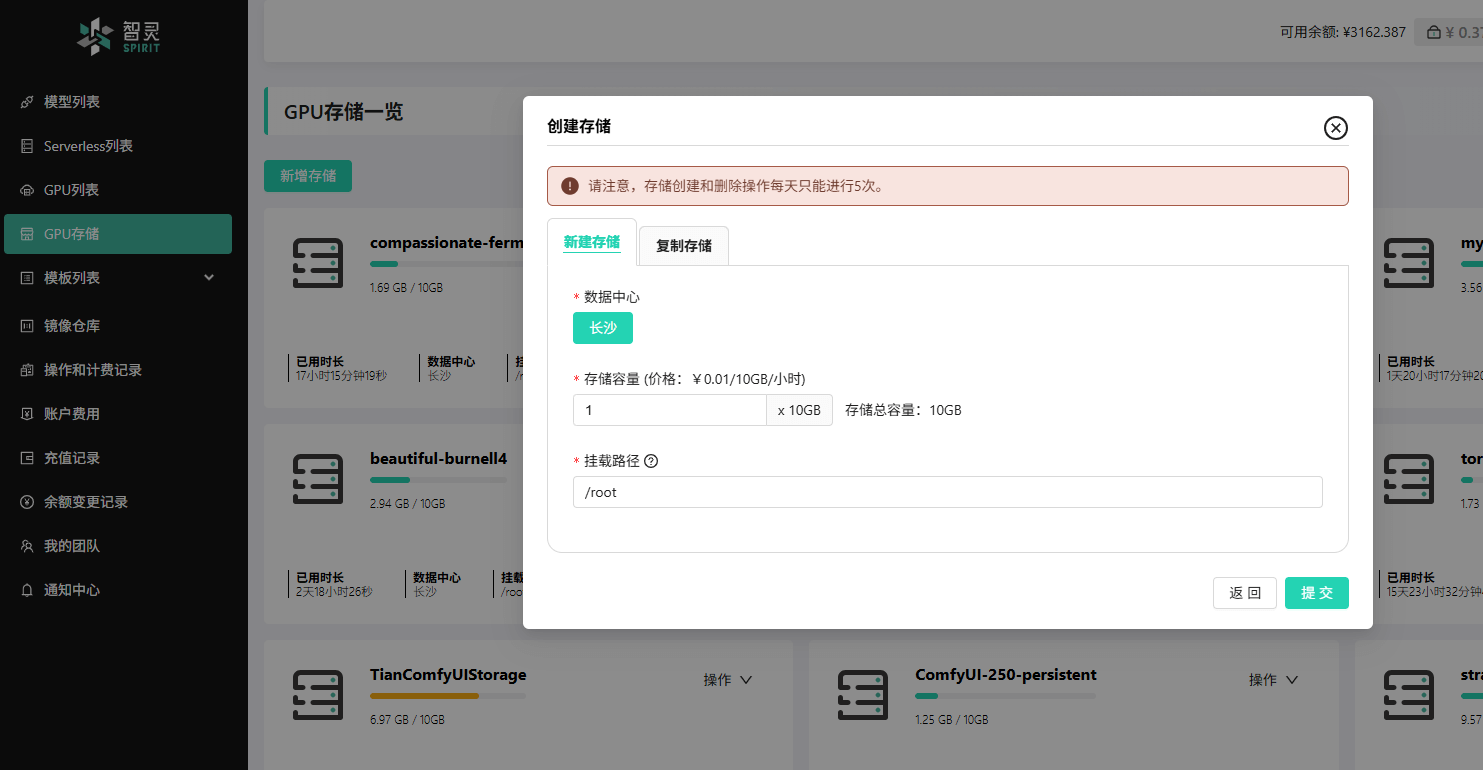
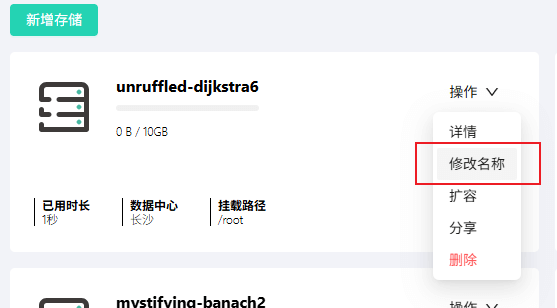
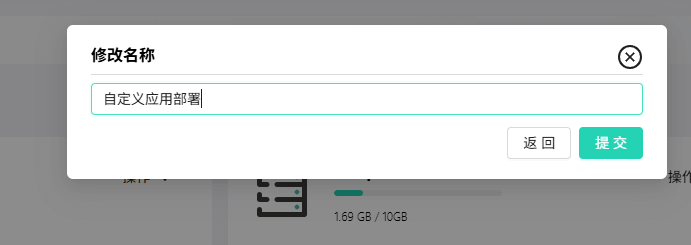
创建完成后,建议为存储重命名以方便管理。此处我们将其命名为 “自定义应用部署”。
步骤二:创建 GPU 实例
接下来,我们将创建一个使用 Jupyter Notebook 模板的 GPU 实例。
在 GPU列表 页面,点击 新增GPU,然后选择 Jupyter Notebook 模板。
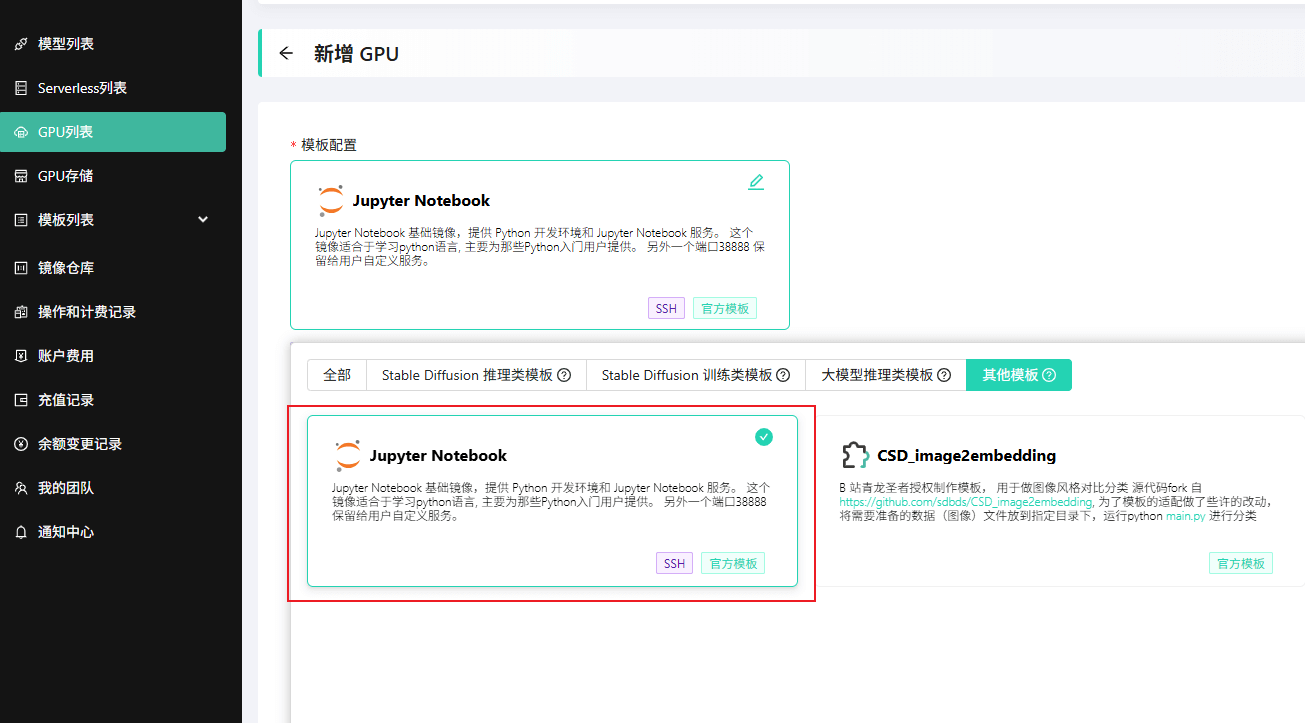
选择合适的 GPU 规格。这取决于您要部署的应用对硬件的具体要求。例如,
AI Toolkit在训练 LoRA 时对显存和内存有较高需求,因此推荐选择4090D或更高规格的配置。在存储配置中,选择我们刚刚创建的 “自定义应用部署” 存储。
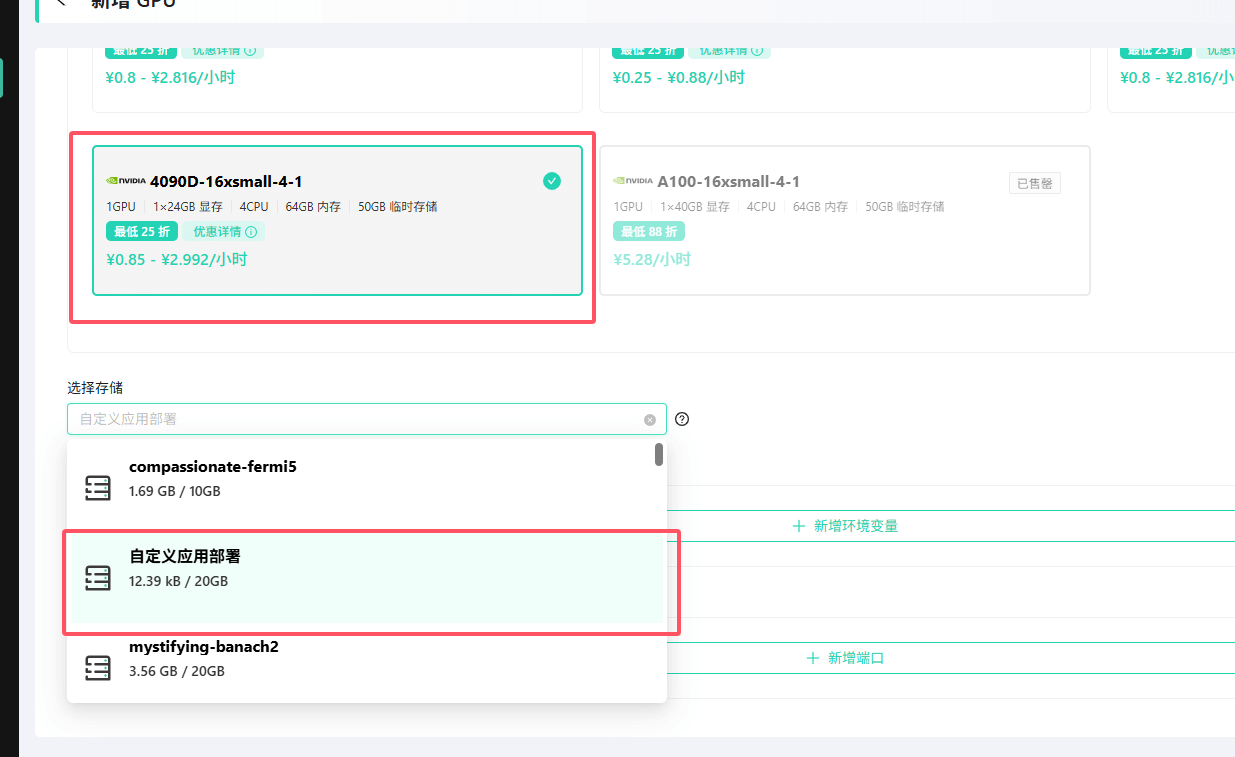
环境变量和端口暂时无需配置,后续可按需调整。
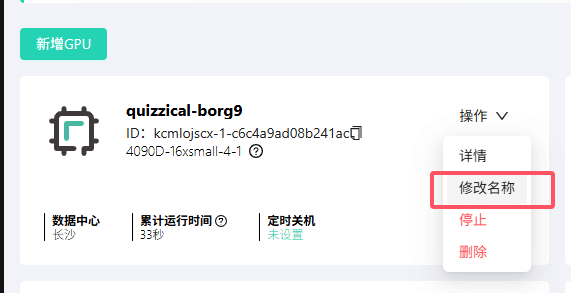
点击 创建。实例创建成功后,同样建议重命名,例如改为 “自定义应用部署”,以便识别。
至此,智灵平台上的准备工作已全部完成。
部署应用
步骤一:克隆应用代码
打开 GPU 实例详情页,点击 打开Jupyter Notebook。Jupyter 环境提供了可视化的文件浏览器和终端,操作更方便。
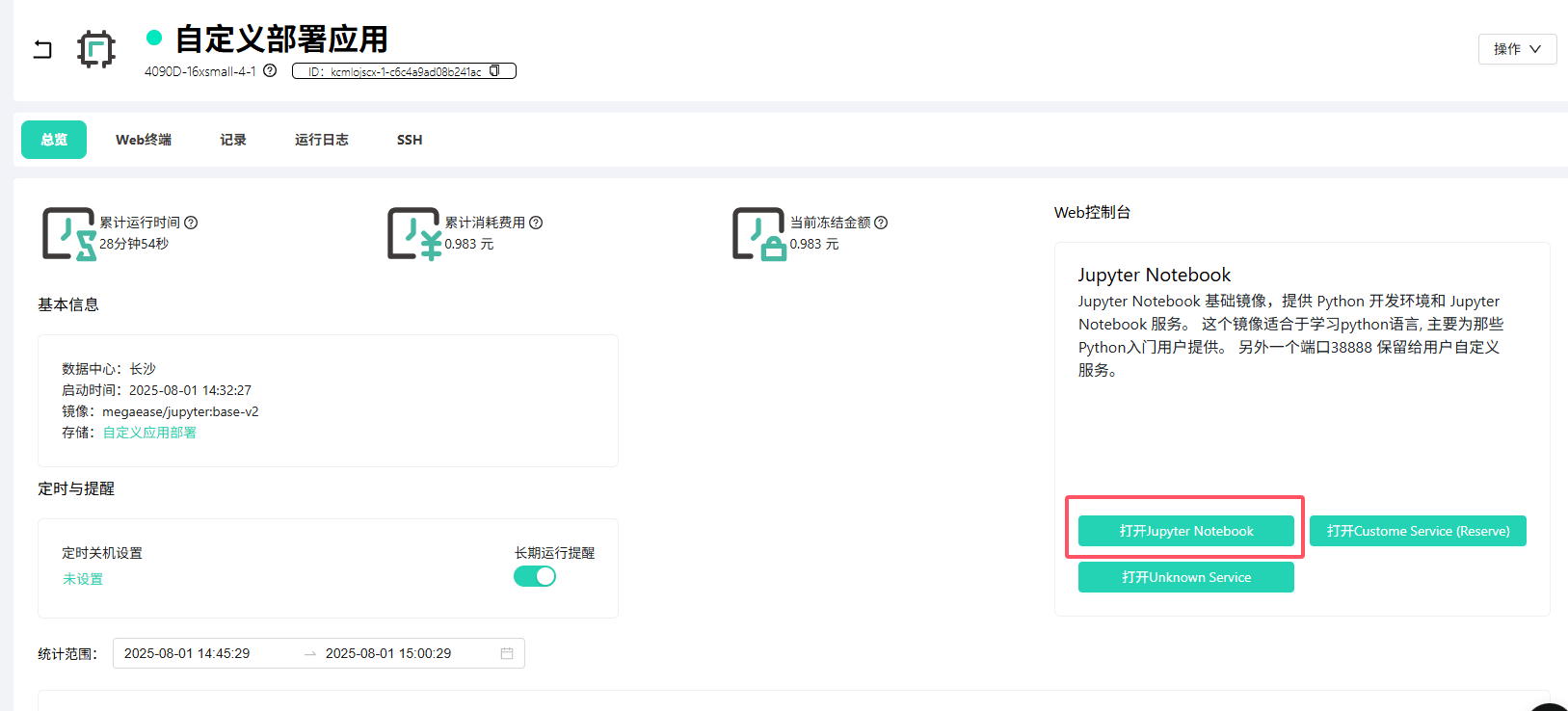
进入到 Jupyter Notebook 页面后,我们从左侧列表中进入挂载的存储目录:
/root,然后点击右侧的终端,会自动进入到对应目录的终端。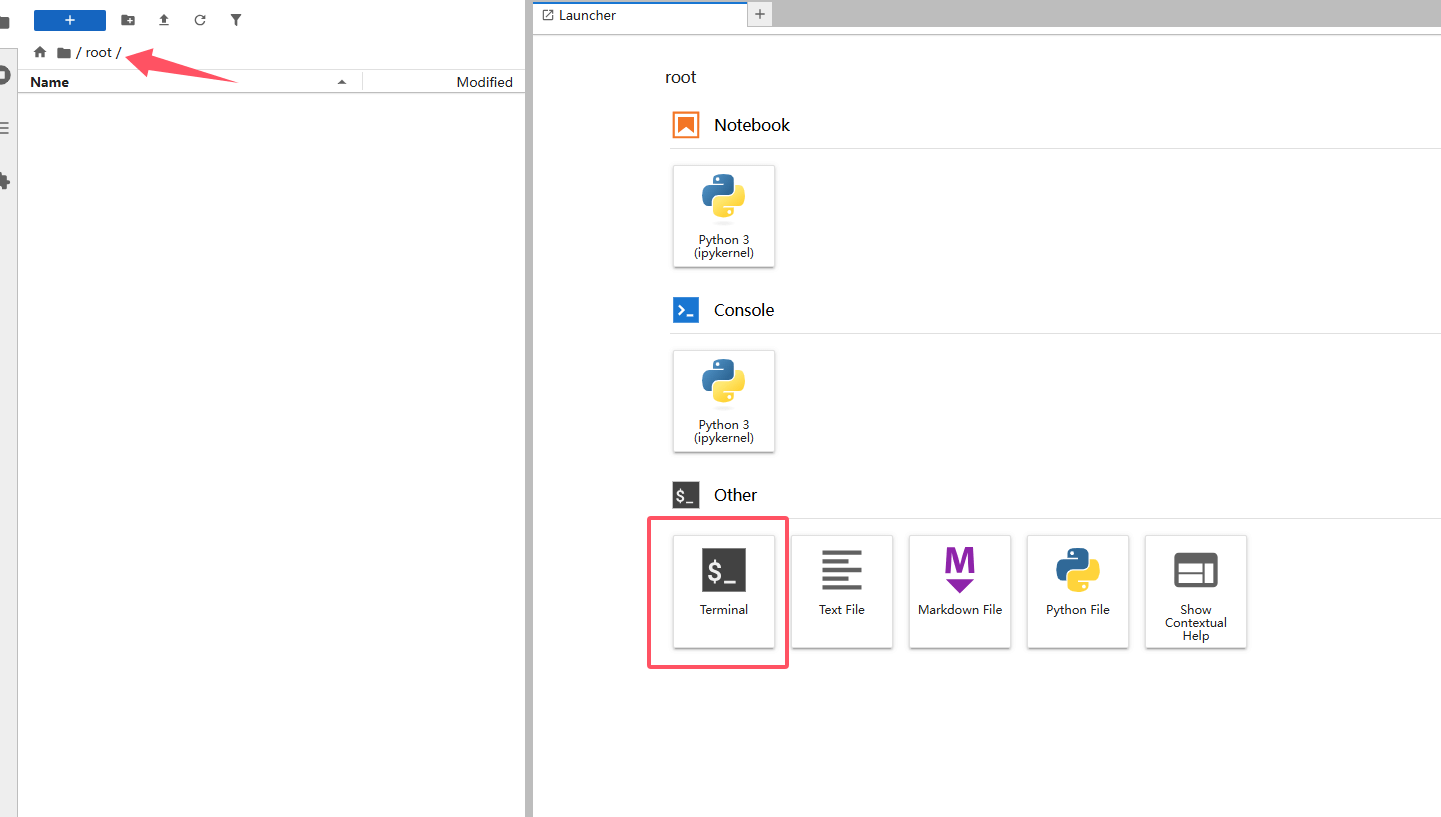
在终端中执行以下命令,克隆 AI Toolkit 的代码仓库:
bashgit clone https://github.com/ostris/ai-toolkit.git克隆完成后,您会在
/root目录下看到一个名为ai-toolkit的文件夹。
步骤二:安装 Python 依赖
根据 AI Toolkit 的官方文档,我们需要在虚拟环境中安装其依赖。
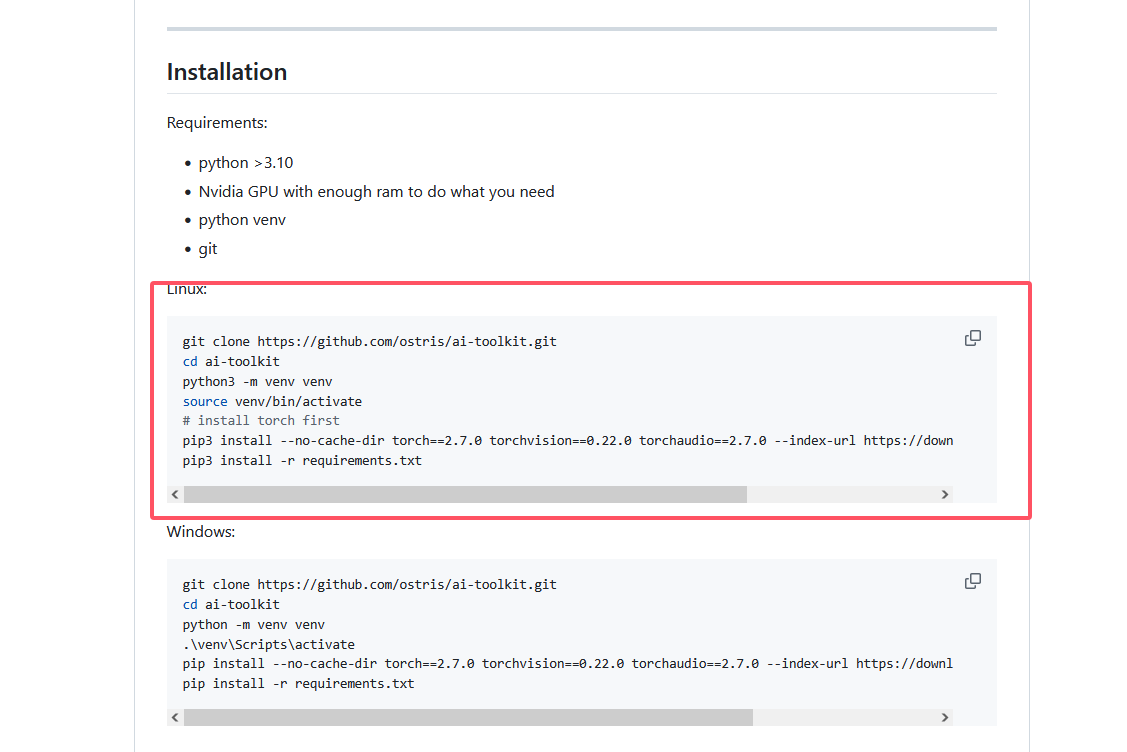
请在刚才的终端中,逐行执行以下命令:
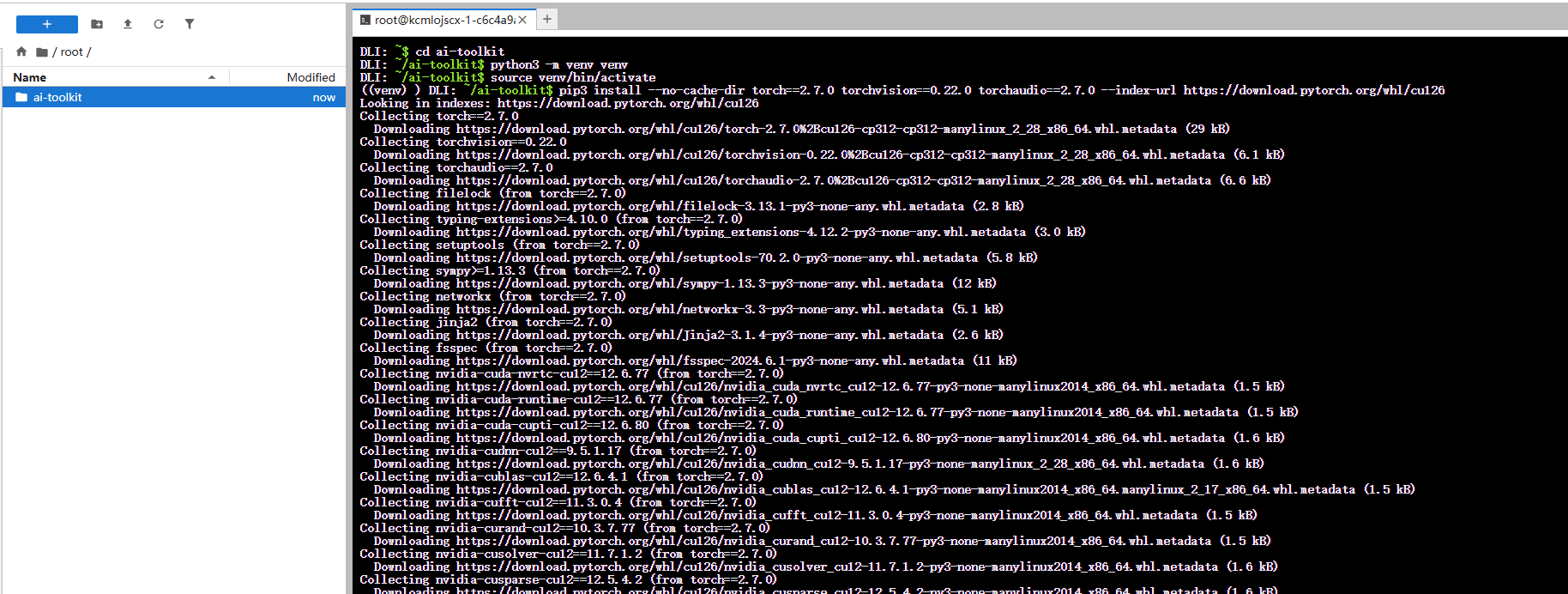
# 1. 进入项目目录
cd ai-toolkit
# 2. 创建名为 venv 的 Python 虚拟环境
python3 -m venv venv
# 3. 激活虚拟环境
source venv/bin/activate
# 4. 安装 PyTorch (注意:版本号已根据官方文档修正)
pip3 install --no-cache-dir torch==2.7.0 torchvision==0.22.0 torchaudio==2.7.0 --index-url https://download.pytorch.org/whl/cu126
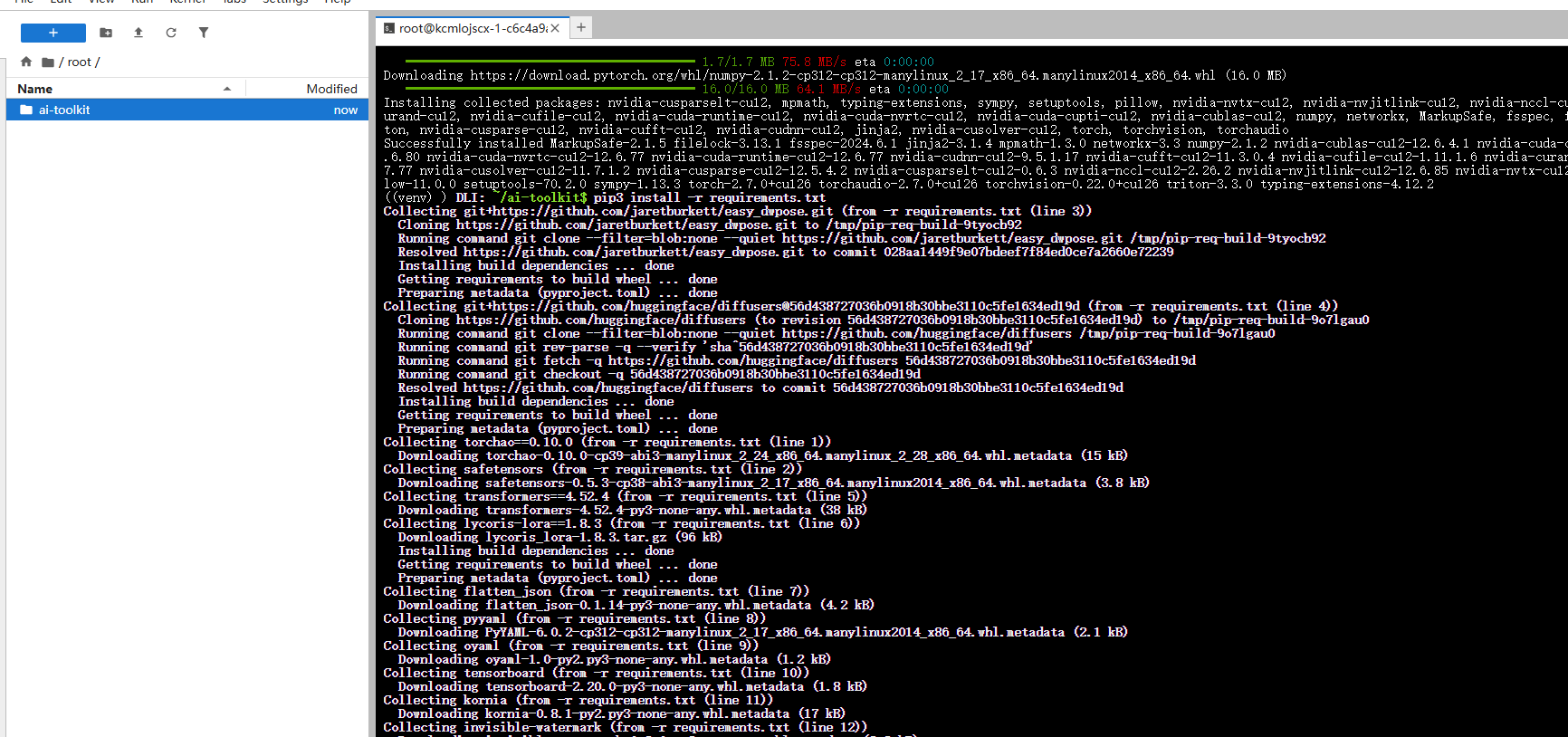
# 5. 安装其他依赖
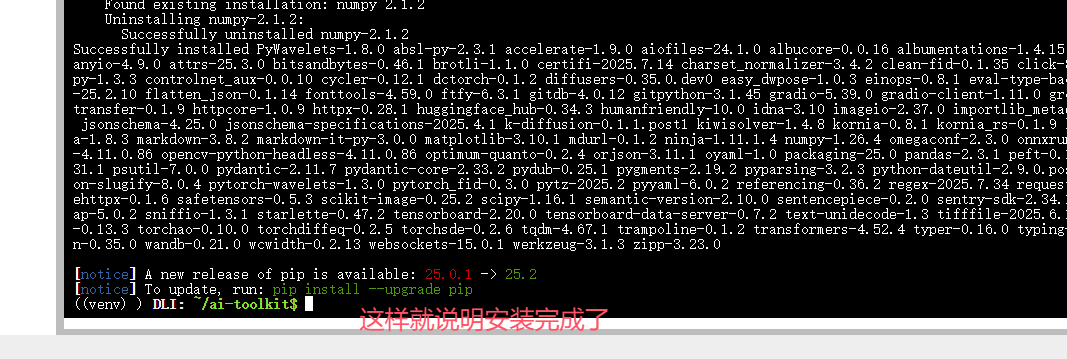
pip3 install -r requirements.txt说明:
venv虚拟环境创建在挂载的/root目录下,因此实例重启后不会丢失。- 依赖包下载需要一些时间,请耐心等待。
步骤三:安装 Node.js 环境并启动 Web UI
AI Toolkit 的 Web UI 依赖于 Node.js 环境(版本 > 18)。
安装 Node.js 版本管理器 (nvm) 和 Node.js
继续在终端中,逐行执行以下命令来安装 nvm 和最新的 LTS (长期支持) 版本的 Node.js。
bash# 安装 nvm curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash # 加载 nvm 环境 \. "$HOME/.nvm/nvm.sh" # 安装 Node.js 最新 LTS 版本 nvm install --lts # 验证 Node.js 版本 node -v nvm current # 验证 npm 版本 npm -v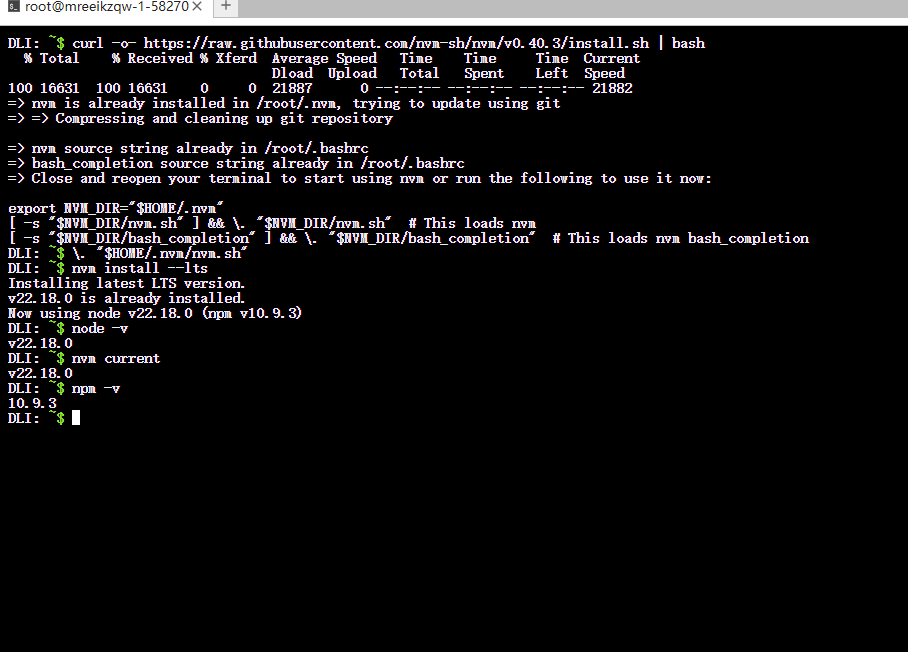
补充说明: 智灵平台默认使用
root账号,其$HOME目录为/root。由于我们的云存储挂载在/root,nvm 和 Node.js 会被安装到该目录下,从而实现数据持久化。处理网络问题并启动 Web UI
在国内环境中,
npm install可能会因为无法访问 Google 字体等资源而失败,并提示:bashError [FetchError]: request to <https://fonts.gstatic.com/s/inter/v19/UcC73FwrK3iLTeHuS_nVMrMxCp50SjIa2JL7W0Q5n-wU.woff2> failed, reason: connect ECONNREFUSED 0.0.0.0:443 at <unknown> (FetchError: request to <https://fonts.gstatic.com/s/inter/v19/UcC73FwrK3iLTeHuS_nVMrMxCp50SjIa2JL7W0Q5n-wU.woff2> failed, reason: connect ECONNREFUSED 0.0.0.0:443) { type: 'system', errno: 'ECONNREFUSED', code: 'ECONNREFUSED', constructor: [Function: FetchError] }
为解决此问题,我们需要修改
package.json文件,让构建过程忽略 TLS 证书验证。在 Jupyter 中,导航到
/root/ai-toolkit/ui目录。右键点击
package.json文件,选择Open With->Editor。找到
"scripts"部分,修改build_and_start的值为:json"build_and_start": "export NODE_TLS_REJECT_UNAUTHORIZED=0 && npm install && npm run update_db && npm run build && npm run start"其实就是在前面加上了:
export NODE_TLS_REJECT_UNAUTHORIZED=0 &&按下
Ctrl + S保存文件。
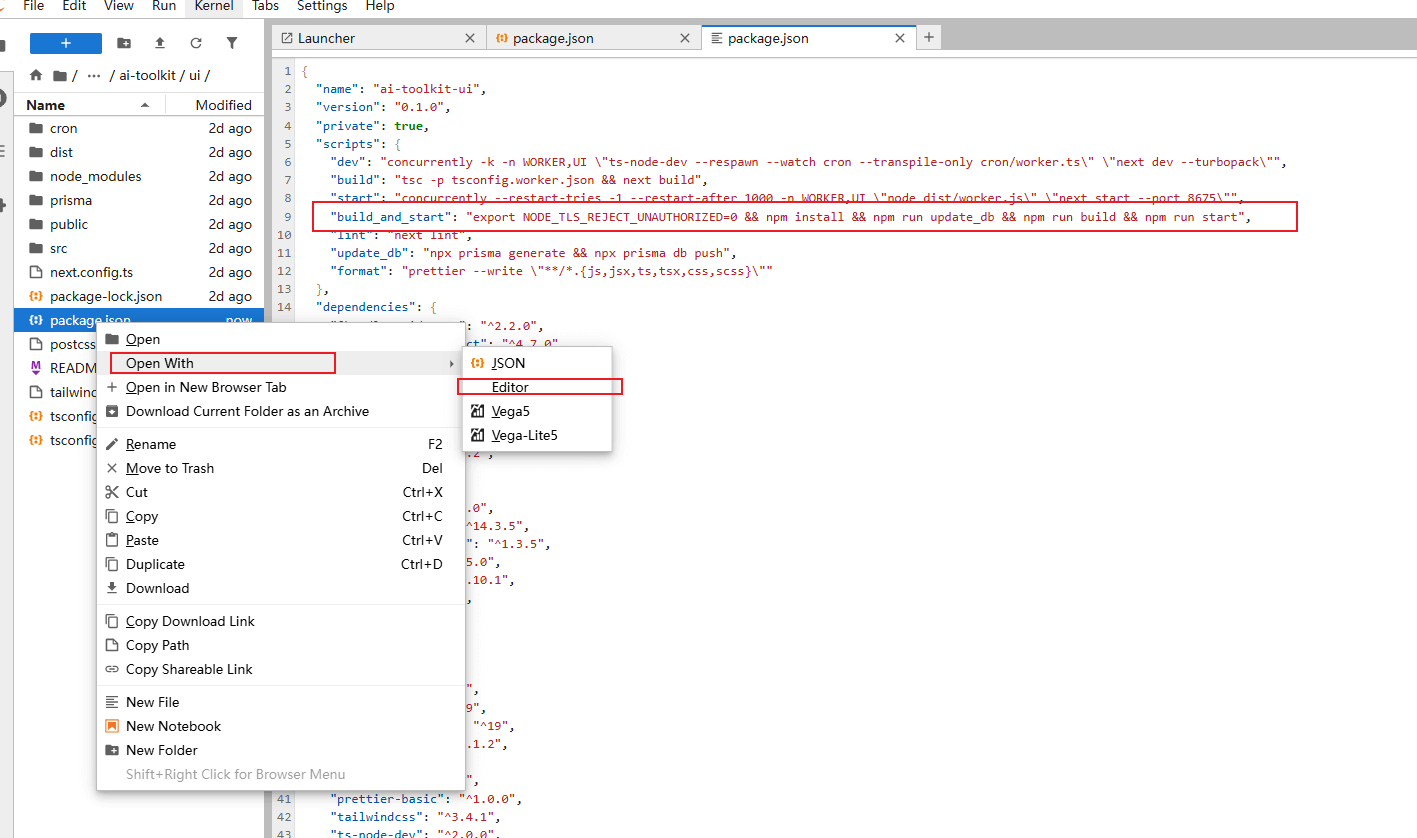
启动服务
现在,我们可以启动 Web UI 了。建议在GPU实例详情页的终端中执行此操作,因为 Jupyter 的终端有时在处理复杂的前端构建任务时可能会不稳定。
回到智灵平台,进入 GPU 实例详情页,打开 终端。
在终端中输入命令:
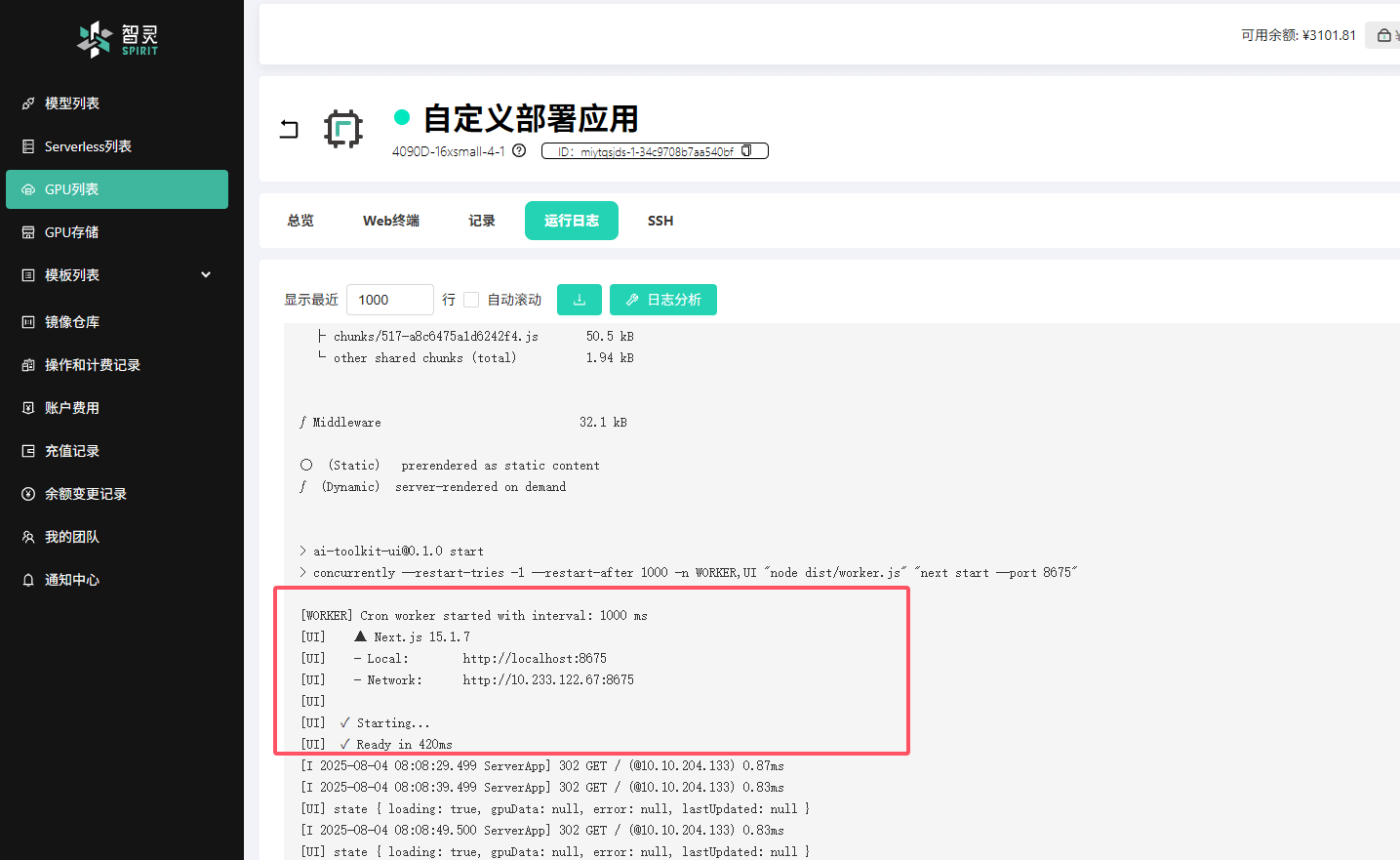
bashcd /root/ai-toolkit/ui npm run build_and_start等待依赖安装和项目构建完成。当您看到类似以下的输出时,表示 Web UI 已成功启动:
text[WORKER] Cron worker started with interval: 1000 ms [UI] ▲ Next.js 15.1.7 [UI] - Local: <http://localhost:8675> [UI] - Network: <http://x.x.x.x:8675> [UI] [UI] ✓ Starting... [UI] ✓ Ready in 450ms记下这里的端口号
8675。
步骤四:配置端口映射
此时 Web UI 仅在实例内部运行,我们需要将其端口映射到公网才能访问。
回到智灵平台,停止 当前的 GPU 实例。
点击 启动,在弹出的配置窗口中,展开 高级设置。
在 端口 设置中,新增一条映射:将内部端口
8675映射出去(这个8675是 AI Toolkit Web UI 的默认端口)。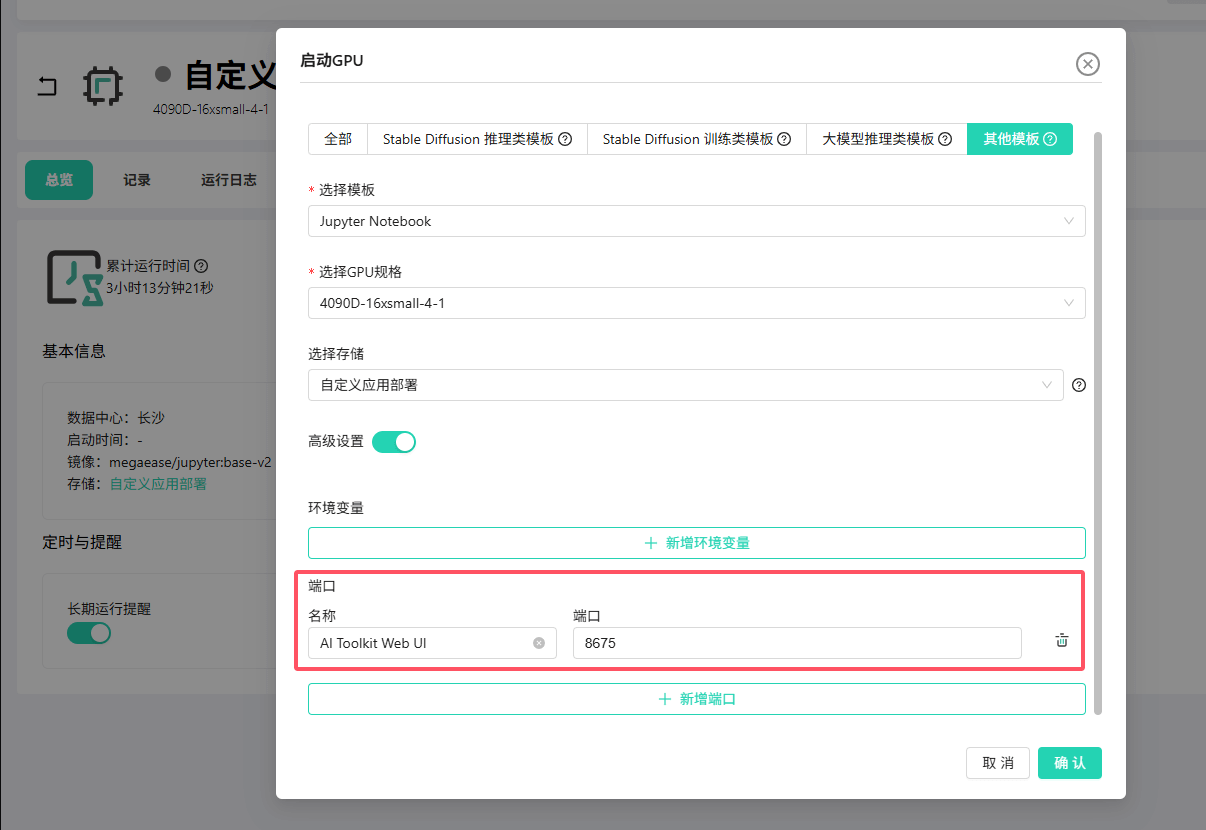
点击 确认,等待实例重启完成。
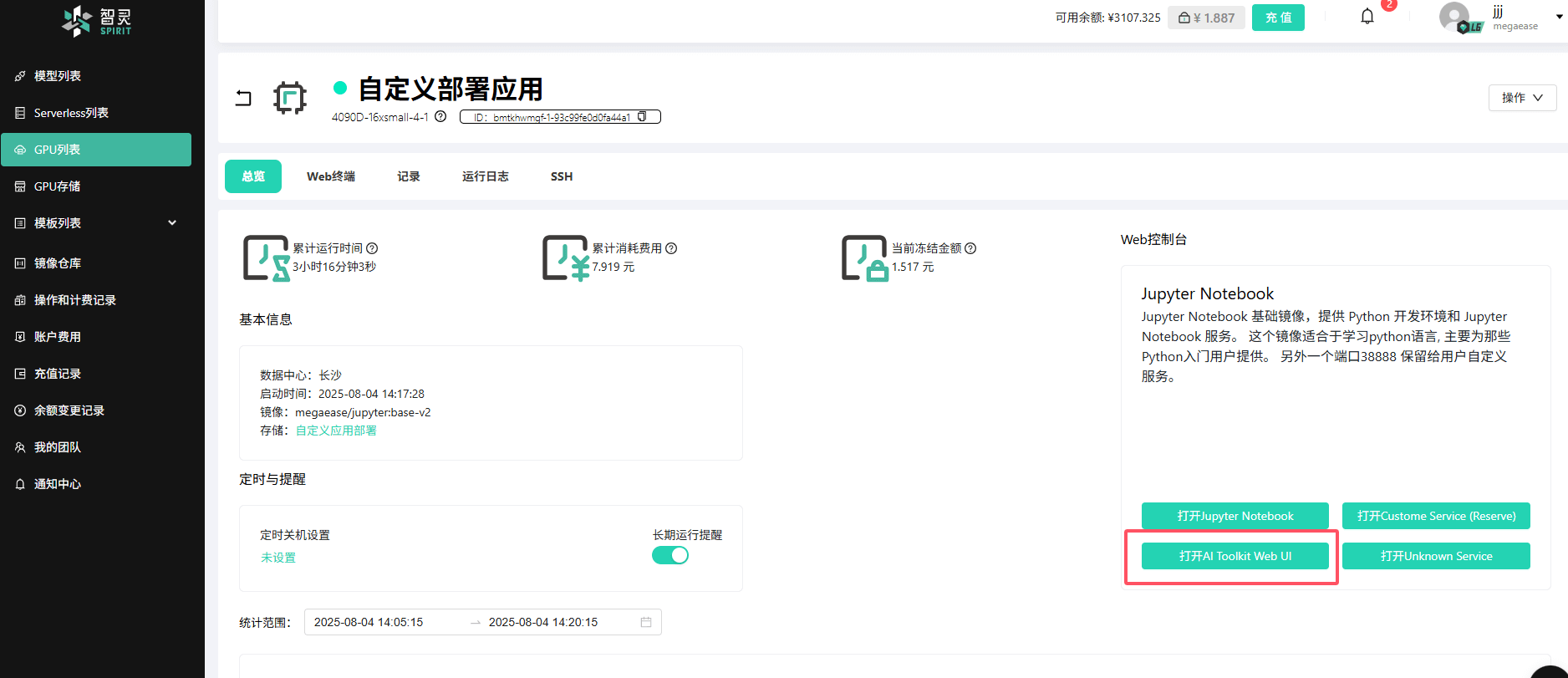
启动完成后,可以在GPU详情页找到打开
AI Toolkit Web UI的按钮,点击按钮打开Web UI页面。目前打开还是无法查看UI界面,因为还没有构建并启动,在GPU详情页的终端中输入以下命令:
bashcd /root/ai-toolkit/ui npm run build_and_start等待依赖安装和项目构建完成。就能看到Web UI的界面了。
步骤五:配置开机自启
为了避免每次重启实例后都需手动构建并启动web服务,我们需要配置一个开机自启脚本。Jupyter Notebook 模板会自动执行位于 /root/hooks/hook.sh 的脚本。
在 Jupyter 中,于
/root目录下创建一个名为hooks的文件夹。在
hooks文件夹内,创建一个名为hook.sh的文件。将以下内容粘贴到
hook.sh文件中:bash#!/bin/bash # 打印日志,表明脚本开始执行 echo "hook.sh started" # 加载 nvm 环境 export NVM_DIR="${HOME}/.nvm" if [ ! -s "$NVM_DIR/nvm.sh" ]; then echo "Error: nvm.sh not found at $NVM_DIR/nvm.sh" exit 1 fi \. "$NVM_DIR/nvm.sh" # 检查 nvm 是否加载成功 if ! command -v nvm &> /dev/null; then echo "Error: nvm failed to load." exit 1 fi # 检查 npm 是否可用 if ! command -v npm &> /dev/null; then echo "Error: npm is not installed." exit 1 fi # 进入目标目录 cd /root/ai-toolkit/ui # 构建并启动服务 npm run build_and_start # 成功日志 echo "hook.sh completed successfully"Ctrl + S保存文件。现在,重启 GPU 实例。启动后,您可以访问GPU实例的 运行日志 页面是否有对应的日志打印来确认脚本是否成功执行。当服务启动成功后,GPU 详情页的
AI Toolkit Web UI按钮(或您配置的端口链接)应该就可以点击并正常访问了。
快速上手:使用 AI Toolkit 训练 FLUX.1-Kontext-dev LoRA
成功部署后,让我们快速体验一下它的核心功能。
选择模型架构
在 Web UI 的
Model Architecture选项中选择FLUX.1-Kontext-dev。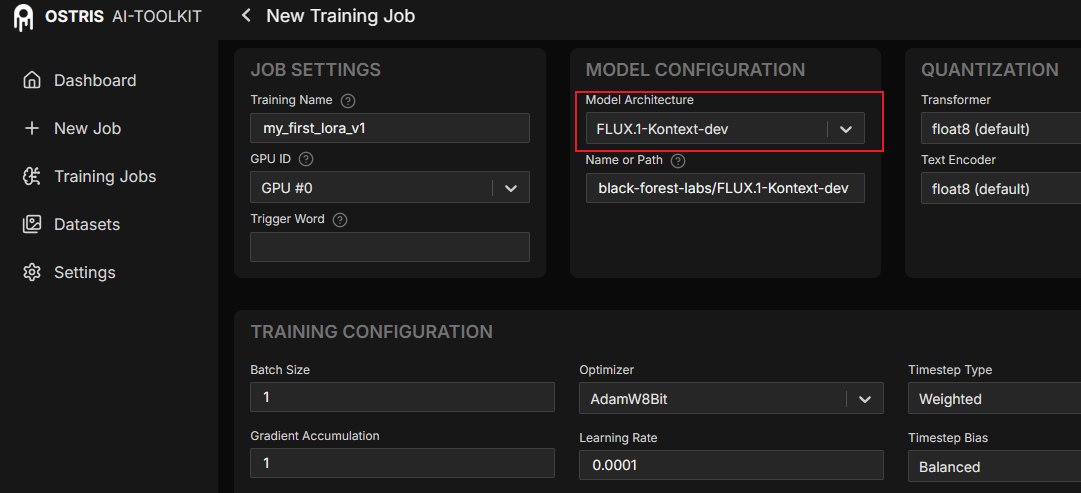
配置基础模型路径
AI Toolkit 需要加载预训练的基础模型。您无需手动从 Hugging Face 下载并上传,可以直接使用智灵平台内置的模型。内置模型位于
/mega-models目录下,不会占用您的存储空间。将
Name or Path字段填写为内置模型路径:mega-models/training/kontext-dev。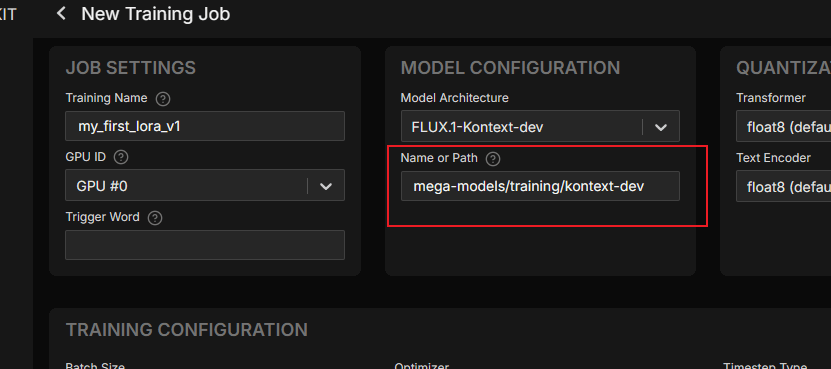
相关资源:
- FLUX.1-Kontext-dev
- 小贴士:智灵平台在
/mega-models目录下内置了大量常用模型。您可以通过ls /mega-models查看,并通过软链接ln -s的方式在您的项目中使用它们。
配置训练数据集
训练 FLUX.1-Kontext-dev LoRA 通常需要两组数据:
- Dataset:包含最终图像和对应文本描述(caption)的数据集。
- Control Dataset:包含生成结果图之前的原始条件图。
在 AI Toolkit UI 上创建并选择相应的数据集,并将对应文件上传。
注意:请根据您的 GPU 显存大小合理设置
Resolutions。对于 24GB 显存,建议分辨率不超过768x768,以免显存溢出。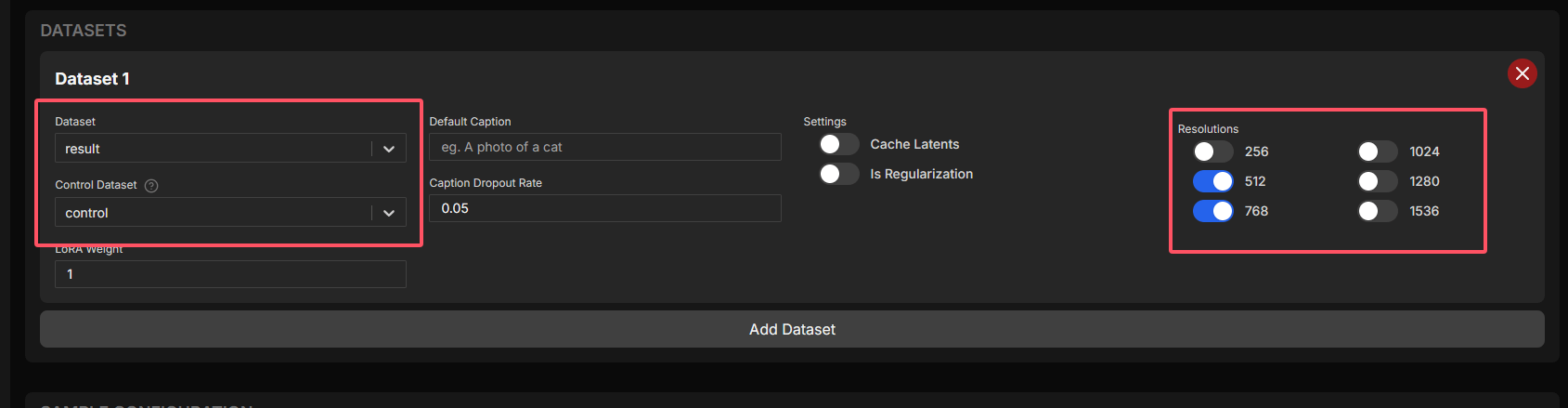
配置训练参数
根据需要调整
Batch Size、Learning Rate、Steps等参数。开始训练
点击右上角的
Create Job创建训练任务。在任务详情页面,点击 开始 按钮即可启动训练。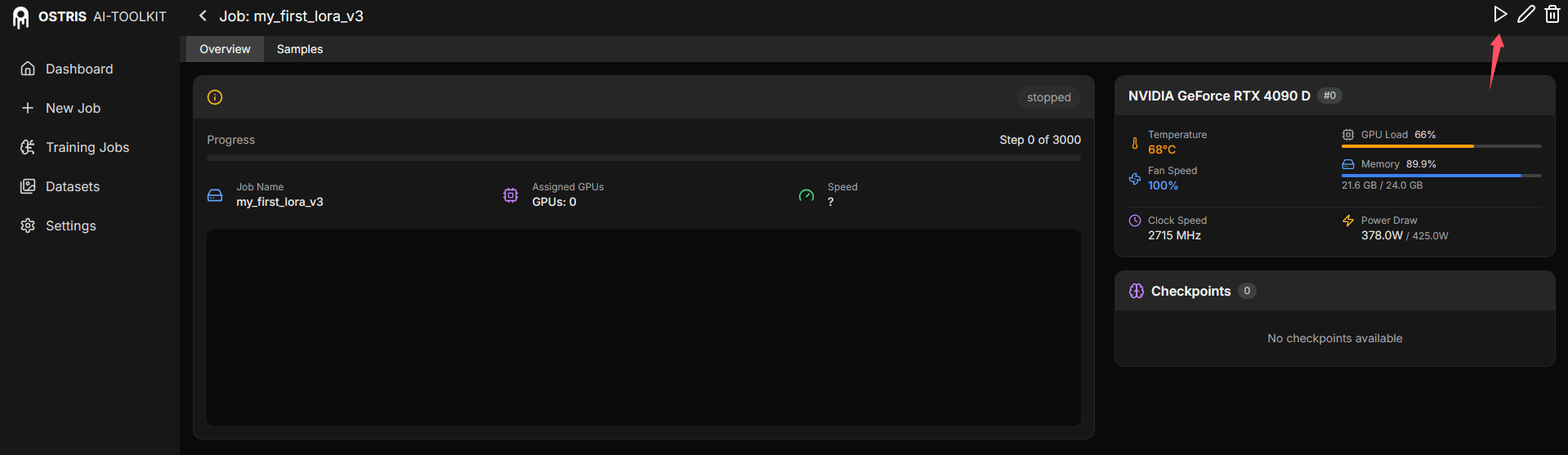
查看结果
训练完成后,生成的 LoRA 模型文件将保存在挂载存储的
ai-toolkit/output/你的任务名/目录下。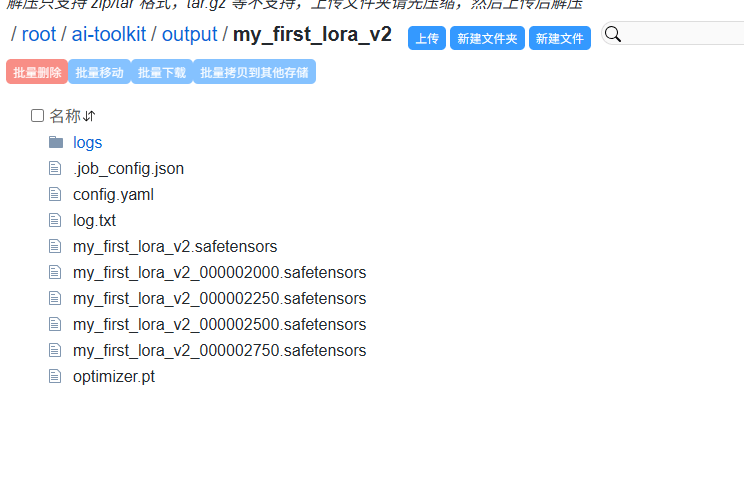
总结
恭喜!通过本教程,您不仅学会了如何在智灵平台上部署一个复杂的自定义 GPU 应用,还成功配置了持久化存储和开机自启,使其成为一个稳定可靠的服务。更进一步,您还掌握了利用平台内置资源进行 AI 模型训练的基本流程。希望这篇教程能为您在智灵平台上探索更多可能性提供有力的支持。