混元视频
智灵训练器支持了混元视频 LoRA 训练,可以在训练页中选择进行混元视频进行训练,步骤和 Flux 训练差不多,先上传图片素材 --> 打标 --> 配置 LoRA 训练参数 --> 开始训练 --> 训练完成。
数据集打标
上传图片素材
切换到混元视频训练页,我们在 第 2 步:训练用的数据 找到数据集目录,选择我们需要上传文件的目录,如果没有可以手动创建。
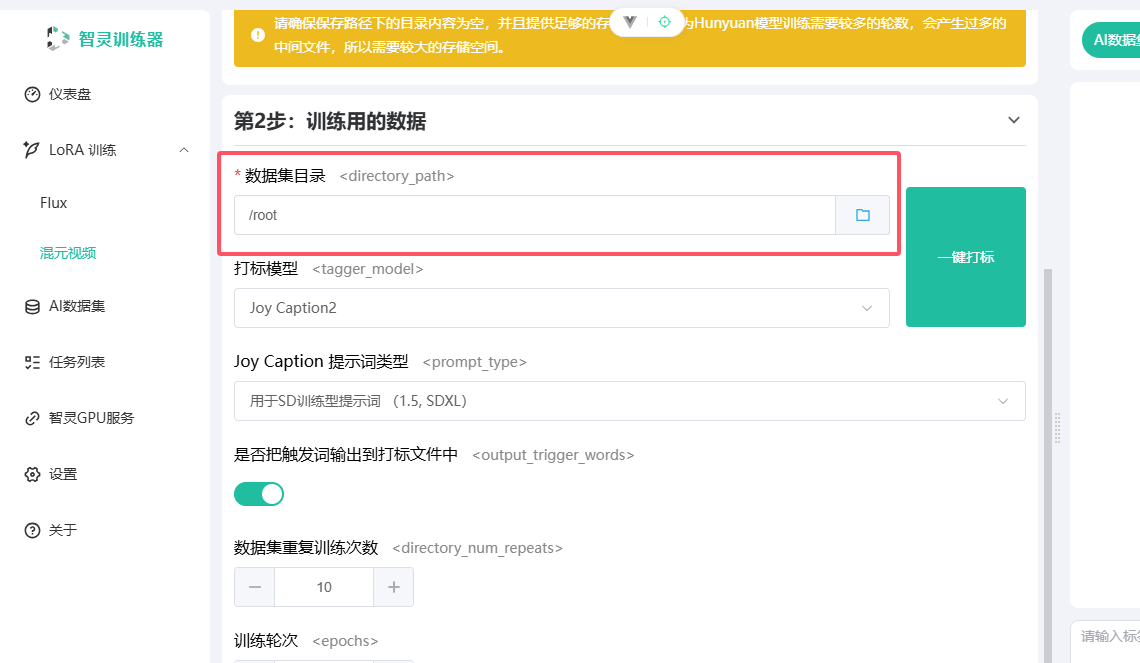
手动创建可以在点击右侧目录选择弹窗中,点击顶部的新建目录按钮新建需要的目录。
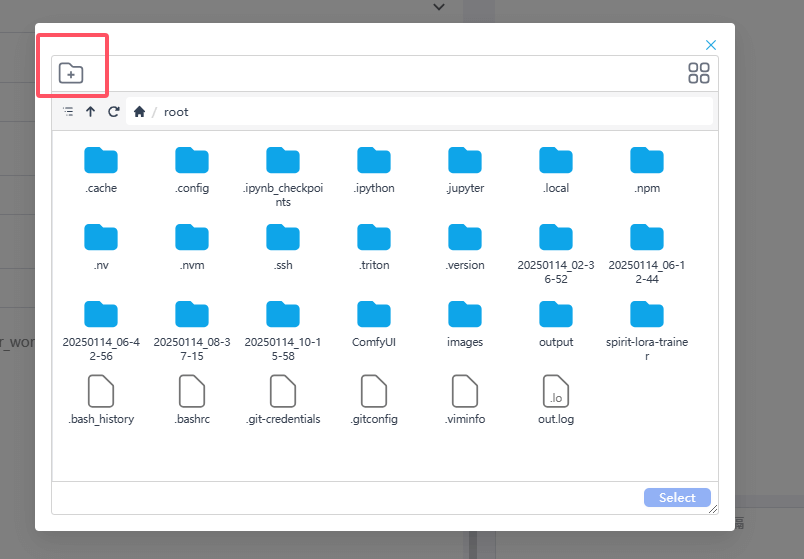
选择好目录后,就可以点击右侧的上传文件按钮进行上传了,上传完成后,可以在右侧看到刚刚上传的素材。
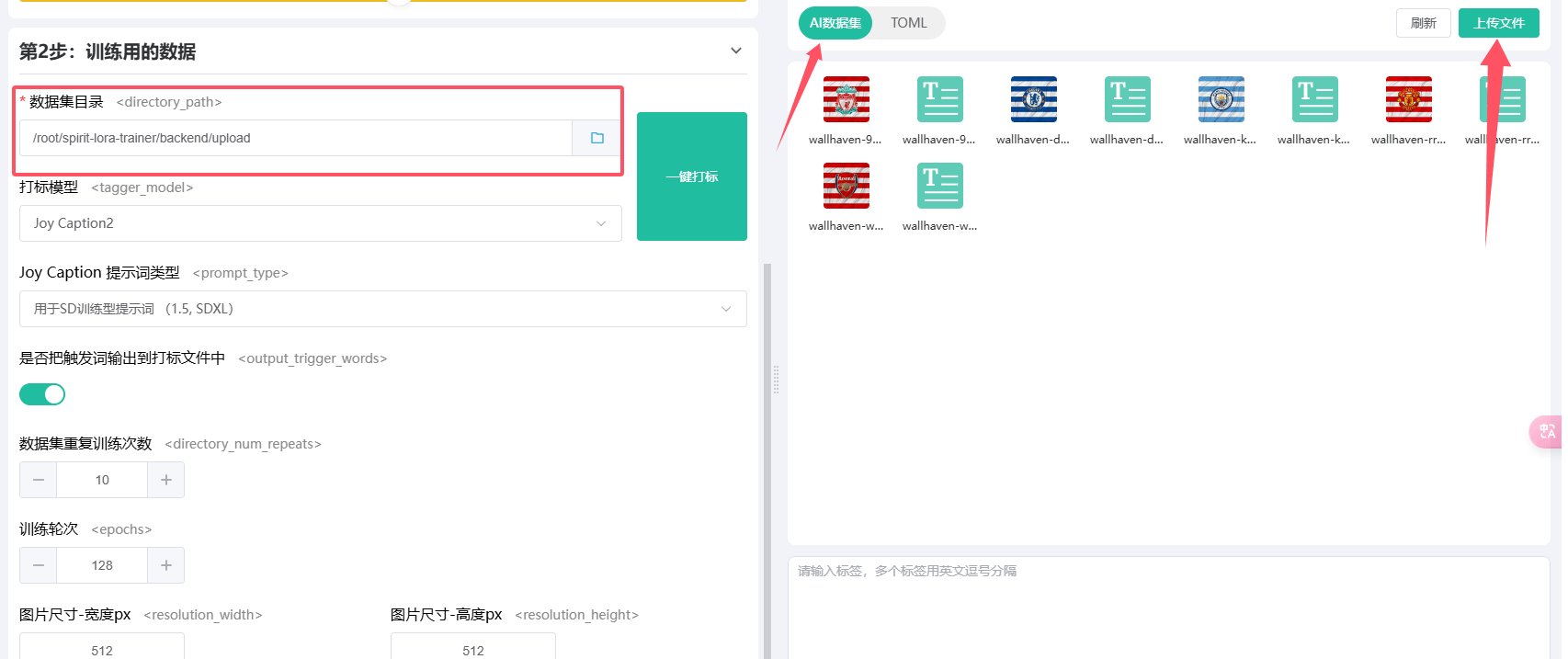
上传完毕后我们就可以选择打标用的模型和打包提示词的类型。
打标
打标模型目前提供了两种:
- Joy Caption2
- Florence2
我们推荐使用 Joy Caption2,因为它对图片的描述偏向自然语言,当然这个看个人需求可自行切换。
目前 Joy Caption2 还支持多种描述类型,这个大家可以根据自己需要自行选择。
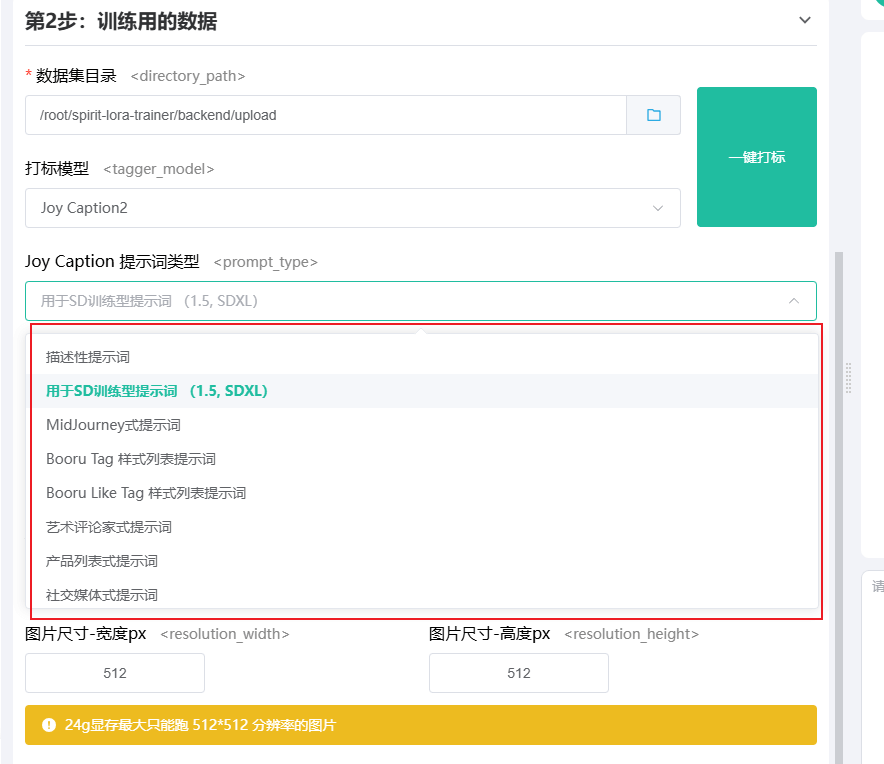
我们还支持将触发词也输出到打标文件中,默认这个选项是开启的,你可以在 LoRA 触发词 输入框中输入你想要的触发词,打标时就会自动输出到打标文件中了。
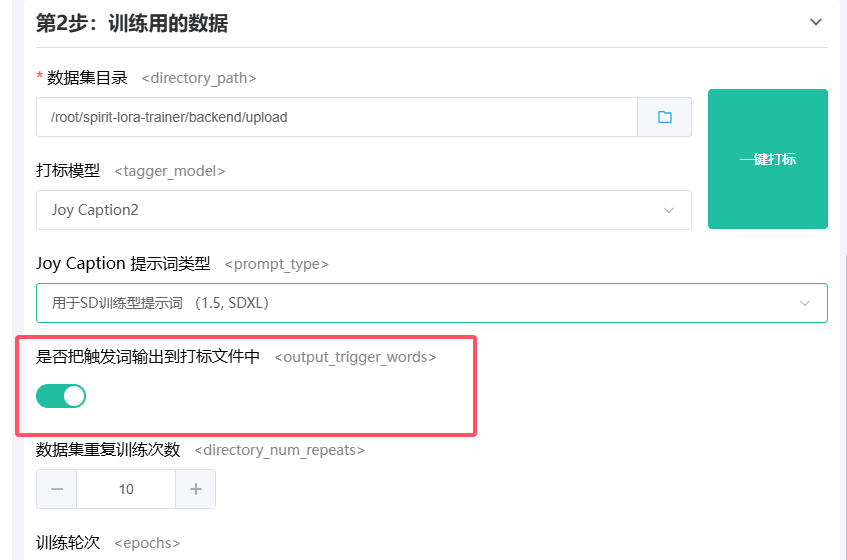
准备好用我们点击一键打标就会将数据集目录中的图片进行打标处理,打标时训练器底部会显示整体的进度,方便你了解打标进度,打标完成后,打标文件就会输出到与图片素材相同的目录下。
打标过程需要加载模型,这可能会花一些时间,请耐心等待。
单独上传打标文件
目前已经支持上传打标文件,但是需要注意,打标文件需要与图片文件名保持一致。
比如我们上传的图片文件名为 1.jpg,那么打标文件就需要命名为 1.txt。
如果已经存在同名的 txt 文件,那么你需要 先删除它,然后再上传新的打标文件。
手动打标或二次编辑
如果你想手动打标,可以在预览界面找到需要打标的图片,右键 --> 手动打标 --> 在底部输入框输入内容,点击保存即可。
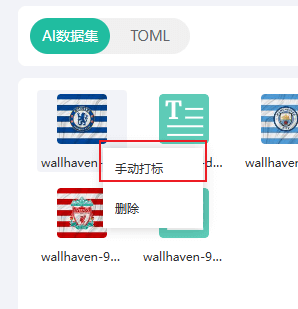
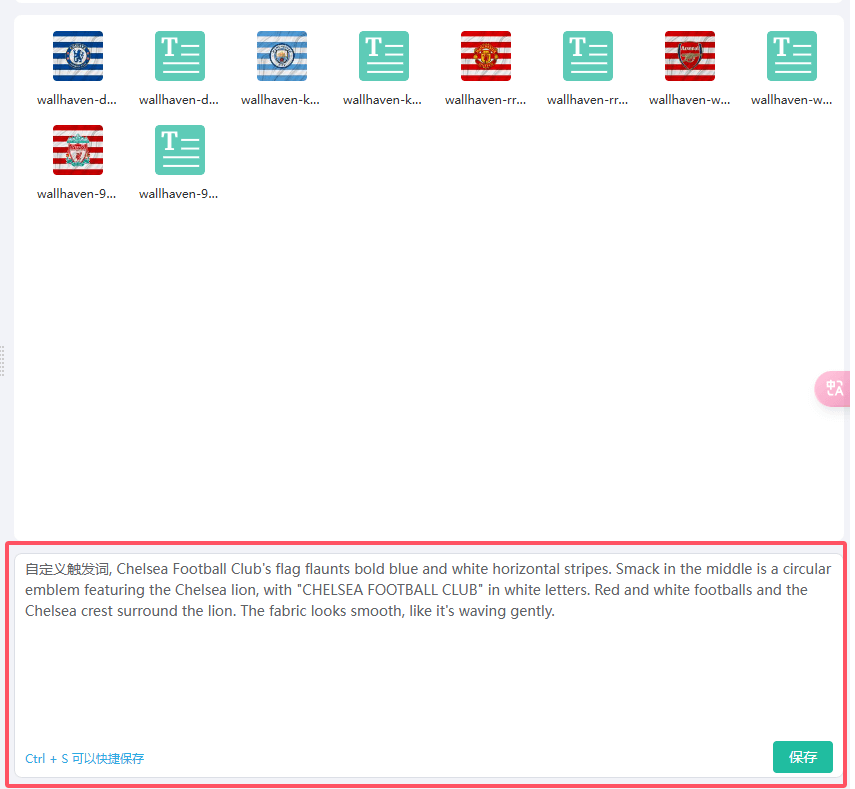
除了手动对图片打标,我们还可以编辑已经生成的打标文件,操作方式也是右键菜单:编辑
编辑操作也是一样,在底部输入框中输入内容,点击保存即可。
训练 LoRA
我们提供了两种训练模式选择,分别是:
- 新手模式
- 专家模式
新手模式可调整的训练参数较少,适合初学者,专家模式则是针对有一定经验的用户,可以调整更多的训练参数。
填写必填参数
必填参数包括: LoRA 触发词、LoRA 保存路径、数据集目录。
以上参数填写完毕就能开始训练了。
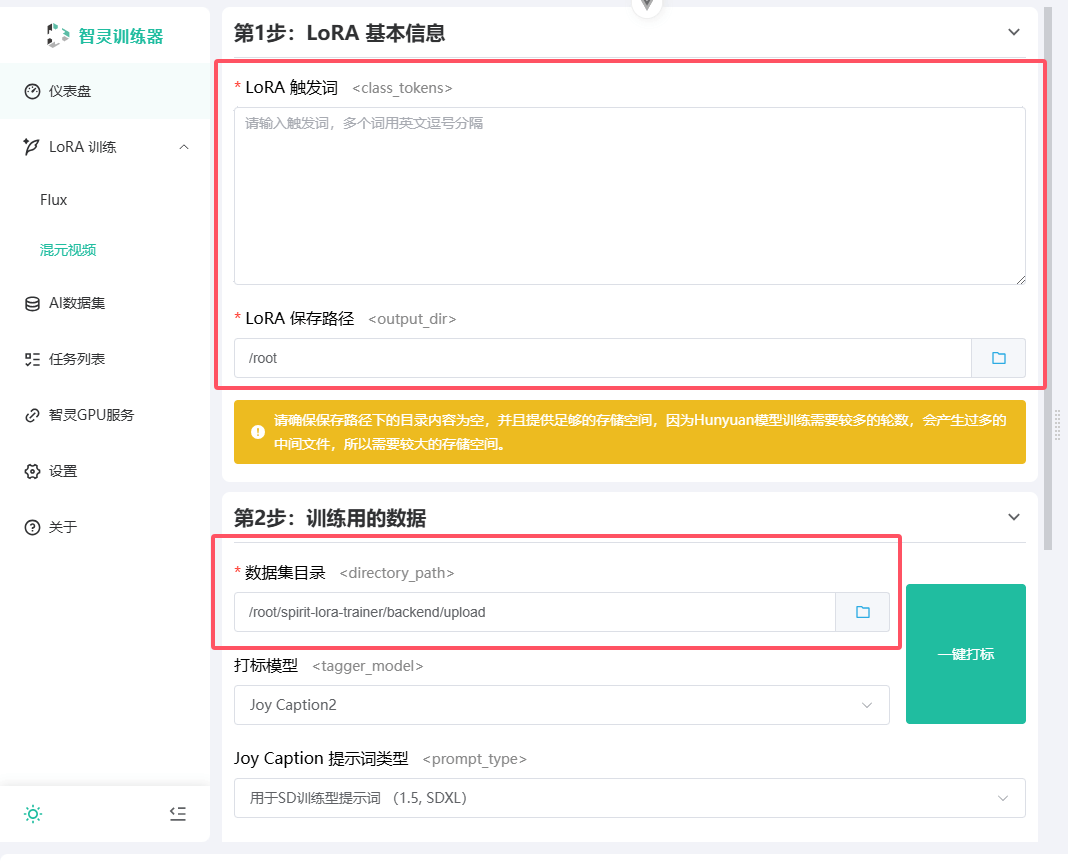
注意:
- 请确保 LoRA 保存路径的目录为空目录,
如果目录不为空,可能会导致训练失败。并且提供足够的存储空间。因为 Hunyuan 模型训练需要较多的轮数,会产生过多的中间文件,所以需要较大的存储空间。- 新手模式中, 默认的训练轮次是128轮, 默认每隔16轮保存一次模型。 注意混元训练的每轮速度相较于Flux的LoRA训练较快, 且默认diffusion-pipe 训练器给的参数是一千轮,考虑到实际的训练场景,我们实际测试下来, 在11张图片的前提下, 每张图片重复
10次的,128轮的训练结果已经可以满意。- 默认情况下,大部分训练参数我们已经根据最佳配置填充了默认值,如果你有需要可以自行修改,也可以开启
专家模式查看更多的训练参数配置。- 间隔几轮保存的模型参数设置需要注意, 间隔轮次必须被总轮次整除。所以为了避免浪费训练时间,
训练的总轮数要是间隔几轮保存模型参数的整数倍。
开始训练
点击右下角:开始训练 按钮开始训练,训练过程中会实时更新训练进度,训练完成后生成的 LoRA 文件会输出到刚刚设置的指定目录下,你可以在 LoRA 保存路径 中查看。

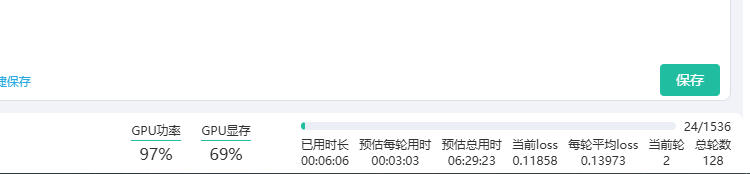
训练过程中会实时更新训练进度,如下图所示:

训练完成后,会有弹窗提示,点击确定按钮即可。
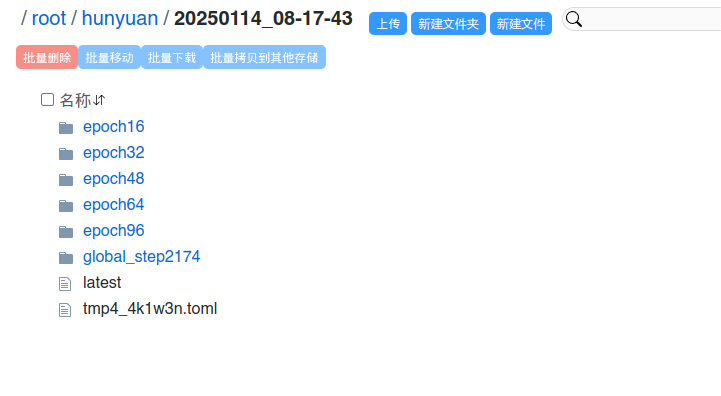
此时我们可以去保存的路径查看刚刚生成的 LoRA 文件。 训练完成后, 在 LoRA 保存路径中会生成一个个子目录,每个子目录中包含了训练过程中的模型文件,你可以根据需要选择最优的模型文件。如下图。 LoRA文件保存在 epoch 开头子目录中。